Artificial Intelligence




FluxAI: Agent-Orchestrated Retrieval Systems for Next-Gen Platform Engineering
This whitepaper explores the “FluxAI” is an innovative AI platform developed to address the challenges of managing and integrating vast, disparate data sources in product engineering across application domains. It addresses both current and new service-related queries, that enhancing user engagement in the digital ecosystem. This platform leverages advanced AI techniques, such as Generative AI, vectorization, and agentic orchestration to provide dynamic and context-aware responses to complex user queries. FluxAI’s intelligent orchestration framework ensures that relevant data is retrieved and presented in real-time, adjusting to the context of each user’s request and role. This adaptable approach not only improves data retrieval efficiency but also ensures timely responses with minimal steps. A case study conducted on financial application resulted in 95% accuracy.
Insights
- Intelligently orchestrate multiple AI services, automatically determining the appropriate service to invoke based on the user's query.
- Cohesive layer that allows users to access information from multiple, disparate knowledge bases without having to interact with each one separately.
- Dynamically adapts its behavior based on user prompts, by retrieving data from multiple services either in parallel or sequentially, depending on the nature of the query.
- Easily incorporate additional AI services or data sources as the system evolves.
Introduction
The rapid evolution of AI technologies has introduced significant opportunities and challenges within the realm of software product engineering [1,2]. One of the challenges faced by organizations today is the effective integration and management of disparate, large-scale data sources. Traditional product engineering has limitations in providing seamless access to critical information, such as real-time updates on spending, health data access, or comprehensive insights across various domains/applications [3,4,5]. These limitations hinder the ability to respond dynamically to the user needs and restrict the potential to deliver seamless, integrated user experience.
To address these challenges, we developed FluxAI, a next-generation AI-driven platform designed to integrate with disparate data sources and provide cohesive, intelligent access to required information. FluxAI introduces a novel orchestration framework that brings multiple domains data together through orchestrating respective intelligent services [6]. The platform’s architecture leverages advanced AI techniques, such as Generative AI (GenAI) [7], vectorization [8,9], and advanced machine learning [10].
One of the key innovations of FluxAI is its ability to orchestrate multiple intelligent agents, which interact with different data sources to retrieve relevant information based on user queries, by organizing information into vector embeddings [11,12]. It dynamically adapts based on user prompts and their specific role within the system, ensuring that the right information is provided at the right time. The platform’s flexible design enables it to apply for a wide range of applications, ensuring it can be adapted to future advancements in the respective application domains.
Background
In the current landscape of AI-powered solutions, the concept of Retrieval-Augmented Generation (RAG) [13,14,15,16] has become a popular approach for improved usage of large language models (LLMs) [15,17,18] with external knowledge sources. However, the existing RAG solutions often present significant challenges for end users in terms of usability and system orchestration. Typically, in these systems, users are required to understand which AI service to call for their specific needs (saving, credit, transfers, fees, limits etc.,). These processes individually interact with each AI services, having their own distinct knowledge base and service framework [19,20,21,22].
For instance, popular frameworks such as LangChain [22,23,24,25] communicate with knowledge bases to retrieve relevant data and generate responses using LLM Models. Each service is designed to handle a specific domain of knowledge, and the user must know how to interact and pick the right AI services.
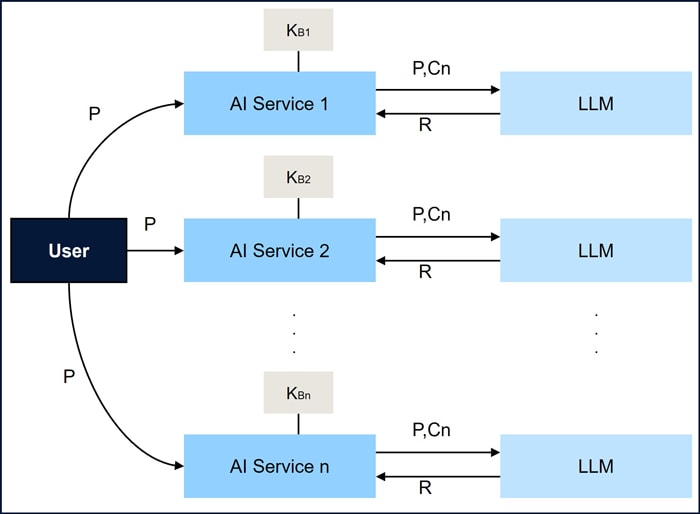
The challenge arises when a product or system relies on multiple AI services, each with its own knowledge repository and operational framework as shown in Figure 1. In such cases, users are expected to know which service to call and in what order. This is a fragmented approach, as users need to manage multiple service calls and may struggle to obtain comprehensive responses. Furthermore, there is no built-in intelligence to orchestrate these services, making it difficult to ensure that the correct data is retrieved. In this approach as shown in Figure 2 multiple services can’t work together seamlessly to answer complex or cross-domain queries from the user [26, 27].
Figure 1: Enterprise Product ecosystem
In essence, while current RAG solutions provide powerful individual capabilities [28,29], they lack the intelligence to dynamically orchestrate multiple services. This leads to a fragmented experience for the user, who need to manually navigate across services individually without any overarching coordination [30]. Therefore, a more integrated system is required to address these challenges, providing users with a smoother, more efficient experience while ensuring that all relevant information is leveraged dynamically.
Figure 2: RAG based Individual AI Services
Objectives of FluxAI Platform
The primary objective is to address the challenges posed by the current Retrieval-Augmented Generation (RAG) solutions. To achieve this, we propose a unified interface for interacting with multiple AI services utilizing an intelligent orchestration framework.
FluxAI Platform’s key objectives are:
- Seamless Service Orchestration: Intelligently orchestrate multiple AI services, automatically determining the appropriate service to invoke based on the user's query [31].
- Unified Access to Knowledge Bases: Cohesive layer that allows users to access information from multiple, disparate knowledge bases without having to interact with each one separately [32].
- Dynamic, Context-Aware Responses: Dynamically adapts its behavior based on user prompts, by retrieving data from multiple services either in parallel or sequentially, depending on the nature of the query [33, 34].
- Scalability and future adaptability: Easily incorporate additional AI services or data sources as the system evolves.
Our Approach to integrating disparate data sources
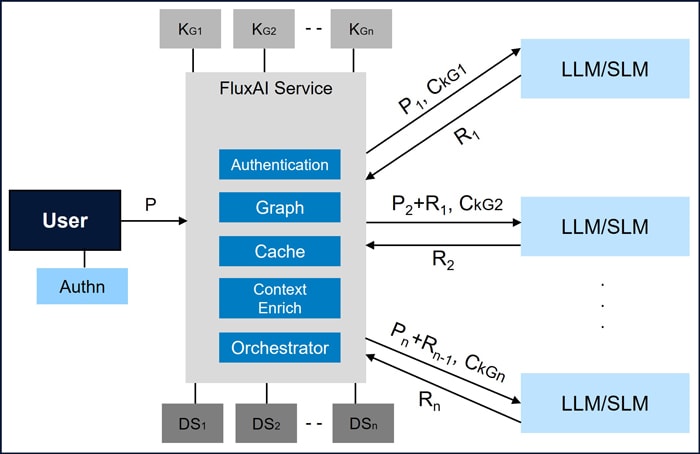
FluxAI employs a layered approach to seamlessly integrate multiple AI services and knowledge bases, ensuring that user queries are answered quickly, accurately, and in context. Dynamically analyzes user inputs, allowing the system to prioritize and organize data retrieval based on the user's intent. Orchestration of AI services using key components are shown in Figure 3. Detailed description of these components is provided here.
Figure 3: FluxAI orchestration of multiple AI Services
Context enrichment engine
FluxAI optimizes response by applying context enrichment rules to user inputs. It identifies key phrases and analyzes the query’s context to fetch data from the appropriate knowledge base [35,36] as shown in Figure 4.
Figure 4: FluxAI’s Context enrichment engine
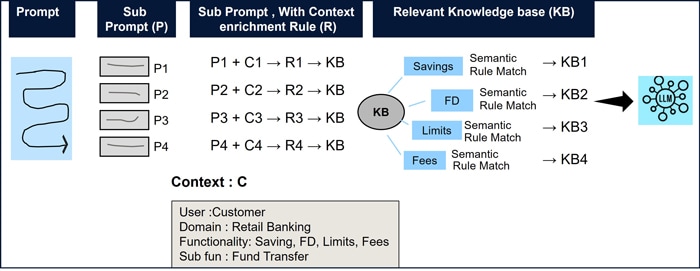
Consider a user query that requires transferring funds from a savings account to a Fixed Deposit (FD) via mobile banking. User query which is called prompt is broken to sub prompts (P1, P2, ... Pn). A context enrichment is applied on a combination of sub prompt and user context (say, Saving and FD) to build a query. This query is used to fetch the response from the knowledge base. It is repeated for all knowledge base (KB1, KB2, ... KBn). For example, context enrichment Rule 1 is for the saving accounts of retail customers. Similarly, a set of rules are built for all the required services.
Caching service
It is used to store frequently accessed data from knowledge bases. Thus, improving performance and reducing latency of the services. Cached data is quickly retrieved, eliminating repeated queries to the knowledge base and ensuring fast response, even with large, complex data sets. This is especially beneficial for real-time data access [37,38].
Figure 5: FluxAI’s Cache Management
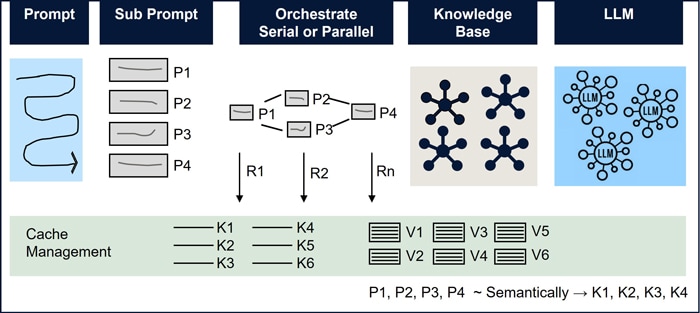
FluxAI breaks the prompt into sub-prompts (P1, P2, ... Pn), processing them in parallel or sequentially as shown in Figure 5. Responses (R1, R2, … , Rn) obtained for each of these sub prompts are cached as Key-Value (KV) pairs in the Cache Management. The stored KV pairs are reused for subsequent user prompts. It reduces any further calls to knowledge base or LLM. Semantically similar Keys are grouped together and while older, unused Keys and KV pairs are removed from the cache.
Graph-based knowledge store
This store is used to index and link data from multiple knowledge bases (KB). It also features a comprehensive Tool Registry, serving as data points for quick retrieval of information of software product/applications. This approach is ideal for managing large, interconnected knowledge sets, facilitating efficient navigation across multiple domains [39,40].
Figure 6: FluxAI’s Knowledge store

For example, documentation, metadata and business data of the software products are represented as nodes and their relationships are depicted as edges in the graph store, as shown in Figure 6. Sub domains and their related business end points are interconnected hierarchically. In the graph, the business details are represented as relationships among the nodes.
Orchestration engine
The orchestration engine is the core component of the Platform. It’s objectives are:
- Understanding the user query and generating appropriate sub-prompts.
- Directing sub-prompts intelligently to appropriate AI services in the required sequence.
- Invoking multiple AI services parallel and/or sequentially based on the complexity of the prompts [41,42].
- Aggregating and consolidating the responses.
To achieve the stated objectives, the orchestration engine’s process flow is designed and illustrated in Figure 7. It has 4 key processes (Prompt, Sub-Prompts, Orchestrator and AI services) to address the objectives. Each of the AI services respond to the sub-prompts based on their built-in intelligence.
Figure 7: FluxAI’s Orchestration engine
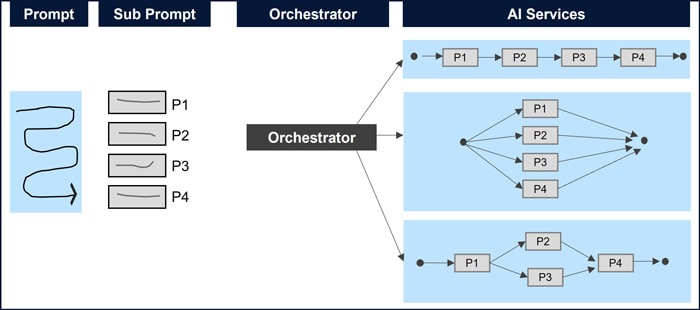
An end-to-end example of the process flow followed on the FluxAI platform is illustrated in Figure 3 and detailed explanation is provided here:
- The user is authenticated, and the software application receives the user input in the form of a prompt (P).
- FluxAI analyzes the user prompt (P) and breaks it down into smaller sub-prompts (P1, P2, ... Pn) based on the context of the product’s functionality, that the user is interacting with.
- FluxAI integrates with various graph-based knowledge stores (KG1, KG2, … KGN) and applies relevant context enrichment rules (Rule1, Rule2, … RuleN) to retrieve the relevant context (CKG1, CKG2, … CKGN) for the respective sub-prompts.
- The orchestration engine determines the optimal sequence for invoking number of AI Services corresponding to the sub-prompts.
- Responses (R1, R2, ... Rn) are received from the AI services by invoking corresponding sub-prompts and results are consolidated.
- Thus, the consolidated response (R) is returned to the user as the final result to the Prompt (P).
- Sub-Prompt and their responses are cached as Key-Value Pairs for subsequent usage.
- As the software application evolves, the FluxAI scales by adding new knowledge stores (KG), Data sources (DS) and AI services correspondingly.
Responsible AI
FluxAI platform is designed to empower enterprise with AI capabilities, ensuring robust data protection and security. It incorporates guardrails on API, and database access to safeguard sensitive information. The platform ensures that only authorized users can interact with the system by implementing AuthN and AuthZ mechanisms, with fine-grained access control. FluxAI strictly allows only search or GET calls, minimizing potential security risks and ensuring data integrity. Ensures compliance with data privacy regulations while enabling businesses to harness the power of AI responsibly.
Case Study and Results
In this section, we analyze how traditional RAG and FluxAI process the user queries as a case study along with their respective results. Example query considered is “Transferring funds from my savings account to a Fixed Deposit (FD) account, what are the limits and applicable fees?”.
In the RAG system, the users are required to manually select the AI service from a range of AI services such as banking transaction services, account details, FD Services, Limits and fee structures. Once the respective service provides the response, the user should corelate the response across multiple services and decide on the next set of actions as shown in Figure 8. This can lead to delays in obtaining a comprehensive response [43].
Figure 8: RAG services in product engineering
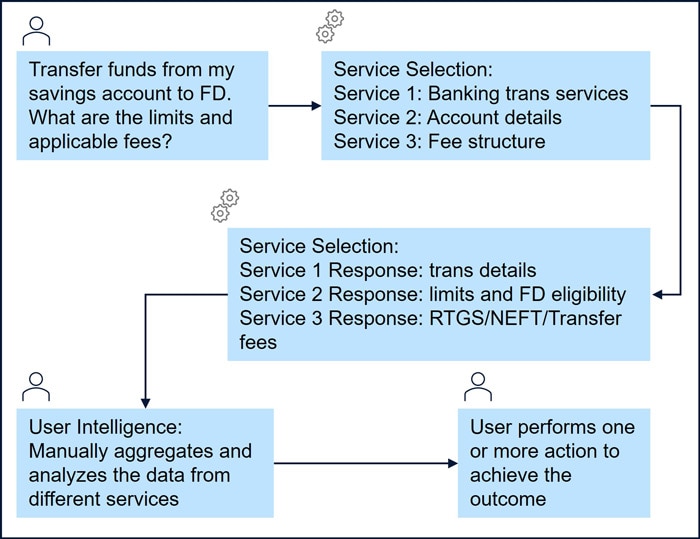
In FluxAI, for the same query, the orchestration engine automatically determines and invokes the necessary AI services based on the query's context. It dynamically accesses AI services, retrieve account details, FD details, transfer limits and applicable fees, without the user requesting to select or manage specific services as shown in Figure 9. [44,45]. Below are the steps in arriving at the final result to the above query.
User Prompt P = “Transferring funds from my savings account to a Fixed Deposit, What are the limits and applicable fees?”
Step 0:
- Creation of the Knowledge graph stores (KG) as part of corresponding AI services.
- KG1 = Graph data store, that contains all types of bank accounts and other details offered by the Bank
- {Public Saving account, Corporate Saving account, Corporate Current Account etc.,}
- KG2 = Graph data store, that contains all types of available FDs and their details offered by the Bank
- {Active: 366 days FD – 8.65% interest, 444 days FD – 8.65% interest
- No Active: 500 days FD – 9.0% interest, 270 days FD – 8.25% interest}
- KG3 = Graph data store, that contains all Bank Policy info, Fees, Limits, taxation, breakage clause and others
- {Within bank transfer: fees 1% via RTGS, 1% via NEFT,
- Outside bank transfer: fees 2% via RTGS, 2% via NEFT}
Step 1:
- Sub Prompt P1= Fetch Customer Banking summary
- Context Enrich 1 = Saving account {KG1 – Public Saving account}
- CKG1 = Saving Banking account and its details {Public Saving account}
- Response 1 (R1)=Customer XXX has greater than ₹100,000 in his saving account
Step 2:
- P2= What are the active FD offered and its details + R1
- Context Enrich 2 = FD account
- CKG2= FD accounts details {Active FDs}
- R2=There are 2 FDs offered with a minimum deposit amount of ₹100,000 for 366 days and 444 days with an interest rate of 8.65%
Step 3:
- P3= Banks policy for limits, charges and others + R2
- Context Enrich 3= Policy related to Limits, Fees
- CKG3= Bank policy {Within bank transfer fees}
- R3=Charges for transfer of amount from Saving account to FD is 1% for NEFT/RTGS
Final Result: You have sufficient balance for the FD transfer. The daily limit is ₹100,000, with a 1% fee for NEFT/RTGS transfers. Proceed with the transfer, and the applicable charges will be automatically deducted.
Figure 9: FluxAI intelligence orchestration services

This highlights FluxAI services enhance user experience by leveraging orchestration engine to seamlessly and dynamically access the services based on the query’s context. This not only eliminates the need for user intervention but also accelerates the response. Delivers a more integrated, user-friendly experience that significantly improves operational efficiency and user satisfaction.
The observations of the case study are summarized in Table 1.
Table 1: Comparison between Traditional RAG and FluxAI Services
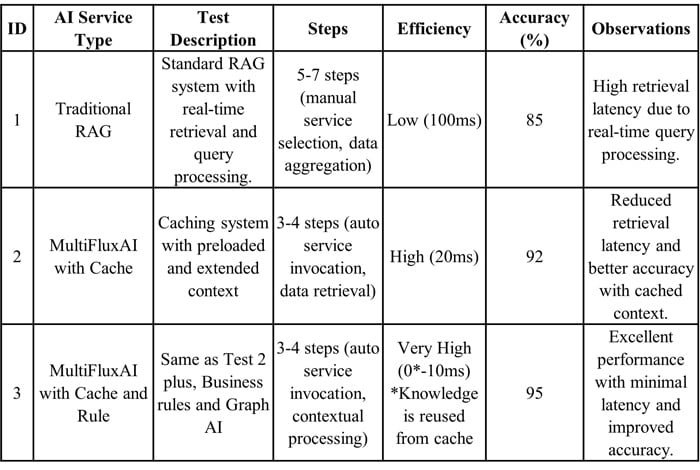
- The FluxAI service outperforms the RAG systems in terms of efficiency, number of steps and accuracy.
- Preloading knowledge and using extended context store allows the AI service to bypass the retrieval process, leading to efficient responses.
- Caching reduced the response times for queries by over 80%, demonstrating performance improvement when frequently queried data is cached.
The advantages of our approach compared to RAG system:
- Dynamically selects AI services based on the query, reducing user effort and speeding up data retrieval.
- The context enrichment engine ensures relevant, personalized results by applying the right context to each prompt.
- Caching and graph-based management improve response times for frequently queried data.
- Harmonizes data from multiple sources, providing a comprehensive view and eliminating fragmented responses.
- The platform’s modular design allows efficient scaling and adapts to evolving needs.
Conclusion
In this paper, we introduced FluxAI, an advanced AI platform designed to overcome the limitations of RAG systems. By integrating intelligent orchestration, caching, context enrichment engine, and graph-based data management. FluxAI addresses the challenges of fragmented data access and manual service selection thus providing a seamless and dynamic user experience across multiple software products\applications.
Using FluxAI, a case study was conducted to evaluate the efficiency of the orchestration engine. The metrics show that FluxAI has higher efficiency, accuracy and minimal number of steps to process different types of user prompts. Future study to be conducted across Retail and Healthcare domains. Chatbot to support cross-sell functionality within an enterprise. Enable businesses to seamlessly engage with customers, offering personalized product or service recommendations based on individual preferences, behaviors, and transaction history.[13].
References
- [1] "AI-Driven Software Engineering: Directions
- [2] The impact of AI and ML product engineering
- [3] Dhaduk, H. - Product Engineering Challenges
- [4] Promact Info Team "Engineering Challenges",
- [5] Upsquare CS Team , "Product Solutions",
- [6] MahoutAI Team Orchestration Agentic Systems
- [7] Lewis, Stoyanov- Retrieval Augmented NLP Tasks.
- [8] Škorić - Text Vectorization via Transformers and N-grams
- [9] Bursztein, Zhang - RETVec: Efficient Text Vectorizer
- [10] Yang, Guo - Parsing & Vectorization in RAG
- [11] Ma, Zhou - Layer-wise Image Vectorization
- [12] Dziuba, Jarsky - Review: Image Vectorization
- [13] Jin, Zhang - RAGCache: Efficient Knowledge Caching
- [14] Liu, Li – CacheGen: KV Cache Compression for LLMs
- [15] Landolsi, Letaief – CAPRAG: Vector & Graph RAG for Customer Service
- [16] Sankaradas, Rajendran – StreamingRAG: Retrieval & Generation
- [17] Minaee, Kalchbrenner – Survey: Large Language Models
- [18] Naveed, Narayanan – Overview of Large Language Models
- [19] Singh, Patel – Agentic RAG: A Survey
- [20] Gupta, Rao – Survey of Retrieval-Augmented Generation
- [21] Wang, Li – Best Practices in Retrieval-Augmented Generation
- [22] Singh, Ehtesham – Agentic RAG: A Survey
- [23] Jeong, Jeong – Agent-Based RAG Using Graphs
- [24] Pandya, Holia – Automating Customer Service with LangChain
- [25] Singh, Ehtesham – LangChain for Mental Health Care
- [26] Sun, Liao – Explainability in Generative AI for Code
- [27] Wu, Hu – Fine-Grained Feedback for LLM Training
- [28] Brynjolfsson, Li – Generative AI at Work
- [29] Radford, Narasimhan – Improving Language Understanding
- [30] Li, Yang – RLHF: Learning Dynamic Choices via Pessimism
- [31] Awad, Awaysheh – BEST: Unified Business Process
- [32] Jeong, Baek – Adaptive-RAG: Adapting RAG
- [33] Shi, Jain – CARING-AI: Context-Aware AR
- [34] Katrix, Carroway – Context-Aware Semantic Recomposition
- [35] Zhou, Zhou – WALL-E: Rule Learning
- [36] Gupta, Ranjan – Study: Sentiment Analysis
- [37] Regmi, Pun – GPT Semantic Cache
- [38] Singh, Fore – LLM-dCache: Tool-Augmented
- [39] Zhou, Du – Graph Learning
- [40] Wang, Fan – KG-RAG: Graph Retrieval
- [41] Rasal – Multi-LLM Orchestration
- [42] Wei, Chen – Internet of LLMs
- [43] Glaese, McAleese – Aligning Dialogue
- [44] Ouyang, Wu – Training LMs
- [45] Phuong, Hutter – Formal Algorithms






Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!