Artificial Intelligence




Methodical ASTs for Precision in AI Driven Mainframe Modernization
Reliable, mainframe-derived ASTs are the crucial bridge connecting COBOL code to core business logic, enabling precise rule extraction for modernization. The recommended hybrid approach in this paper synergizes mainframe accuracy with AI's analytical power, overcoming COBOL decoding complexities. This delivers accurate, contextual understanding, empowering AI for efficient code analysis and transformation. Ultimately, this accelerates modernization, reduces risk, and preserves vital business logic. This document details an integrated framework leveraging deep mainframe expertise and AI's potential to engineer a revenue-optimized solution by embedding mainframe-generated AST data within advanced AI/ML workflows, driving exceptional business results and faster revenue realization.
Insights
- Mainframe mastery, amplified by AI intelligence, creates an unstoppable force for modernization and innovation.
- Automated ASTs from Metadata ensures precise modernization, avoiding parsing errors.
- AI gains deep COBOL understanding when it is built on reliable metadata.
- A hybrid approach of mainframe metadata plus AI automation can deliver accurate, contextual COBOL analysis outcome.
- Reliable ASTs extract key business rules, thereby streamlining migration and documentation processes.
- Metadata-driven ASTs minimize risk, speeding up COBOL/Mainframe modernization and empowering Developers.
Introduction
This paper presents a system-level methodology for automated COBOL AST generation, leveraging metadata to minimize parsing errors. By bypassing manual parsing of COBOL programs, it delivers accurate ASTs, crucial for mainframe modernization. AI-driven tools can utilize this metadata for automated documentation, visualization, and code transformation, addressing the diminishing COBOL skillset. This approach accelerates migration, reduces risk, and empowers developers from modern technologies to understand legacy systems efficiently. The scope of this document is IBM Enterprise COBOL for z/OS.
Why not just throw COBOL at AI and let it figure it out?
The answer lies in the fundamental limitations of AI's ability to understand context and nuance, especially with legacy systems.
Here are some clear challenges:
- COBOL retains the core COBOL complexity: verbose syntax, nested control structures, and implicit data definitions.
- Due to its decades-long existence, mainframe code exhibits significant variations in style and structure resulting from extensive evolution.
- While there is a large amount of COBOL in production, access to that data for AI training is severely restricted due to security and proprietary concerns.
- There are variations based on COBOL compiler versions and site-specific extensions.
- COBOL is deeply intertwined with system services like CICS, DB2, IMS, and MQ. AI models require a profound understanding of these system dependencies to accurately parse and interpret the code.
- Understanding the data flow between COBOL programs and these system components is crucial, and that requires extensive knowledge of z/OS internals.
- COBOL programs often contain core business logic that is deeply embedded within the code itself.
- Extracting and understanding this logic requires not only parsing the code, but also understanding the business domain that it implements.
- There are fewer modern AI development tools and libraries specifically tailored for COBOL.
- The expertise required to build and deploy AI models for COBOL is scarce, as many AI practitioners lack experience with mainframe systems.
AI vs COBOL Complexity: The Contextual Segmentation Bottleneck
Analyzing and modernizing COBOL with AI is significantly impacted by how the code is divided, or "chunked." No single chunking method works best; the ideal approach depends on the AI's goals, the COBOL code itself, and the AI model's strengths. A major challenge is the "contextual segmentation bottleneck," where AI struggles to break down code meaningfully while retaining crucial inter-part relationships. Basic chunking often misses complex control and data flow, leading to a loss of overall program understanding. Context-aware segmentation is therefore critical for AI to accurately grasp the intricacies of these legacy systems.
These are the standard chunking approaches for COBOL in AI analysis, along with their top strengths and weaknesses:
| Chunking approach | Example (Legend: Chunk1 Chunk2) |
Top advantages | Top disadvantages |
|---|---|---|---|
| Line-based | 00010 MOVE A TO B. 00020 ADD 1 TO C. 00030 DISPLAY B. 00040 IF C > 10 THEN 00050 PERFORM PARA-X 00060 END-IF |
|
|
| Paragraph-based | PROCEDURE DIVISION. PARA-1. MOVE A TO B. DISPLAY B. PARA-2. ADD 1 TO C. IF C > 10 THEN PERFORM PARA-X END-IF. |
|
|
| Section-based | PROCEDURE DIVISION. MAIN-LOGIC SECTION. MOVE 'HELLO' TO A. DISPLAY A. ERROR-HANDLING SECTION. DISPAY 'ERROR OCCURRED'. |
|
|
| AST-based | IF CUSTOMER-TYPE = 'PREMIUM' PERFORM CALCULATE-DISCOUNT MOVE DISCOUNT TO FINAL-PRICE ELSE MOVE BASE-PRICE TO FINAL-PRICE END-IF. |
|
|
| Control-flow based | PERFORM A THRU C STOP RUN. A. MOVE 1 TO X. B. ADD 1 TO X. C. DISPLAY X. |
|
|
| Dataflow based | MOVE INPUT-REC TO WORK-REC. MOVE WORK-FLD-1 TO OUTPUT-FLD-A. MOVE WORK-FLD-2 TO OUTPUT-FLD-B. WRITE OUTPUT-REC. Assumption: All the above lines deal with moving and writing of related data |
|
|
There is no universally best way to chunk COBOL for AI. It depends on the AI's goal, the COBOL code's style, and the AI model's strengths. For in-depth analysis like understanding meaning and refactoring, AST-based chunking is often best as it captures code structure. Paragraph-based chunking is a good starting point by leveraging COBOL's own organization. Control-flow chunking helps with execution analysis, while data-flow chunking is key for understanding data handling. Line-based is too simple, and section-based creates chunks that are often too large for effective detailed analysis. Often, a combination of methods is the most effective strategy.
Recommended solution: Hybrid Approach
For deep code understanding and refactoring, Abstract Syntax Tree (AST)-based chunking, which captures the code's structural intricacies, often proves most beneficial. Combining ASTs with other methods like paragraph-based (for logical units), control-flow (for execution paths), or dataflow (for data handling) chunking in a hybrid approach further enhances AI's comprehension.
However, a truly robust solution for COBOL modernization leverages a broader hybrid approach that integrates AI with the authoritative source of truth: mainframe metadata. This metadata, encompassing data dictionaries, copybooks, and system catalogs, provides AI with the precise context and relationships necessary for accurate analysis, potentially even informing the generation of enriched ASTs. By feeding AI with this reliable metadata, organizations can minimize errors and misinterpretations inherent in purely syntax-driven AI analysis. Simultaneously, AI's pattern recognition and automation capabilities streamline time-consuming modernization tasks. Crucially, human oversight remains essential to validate AI outputs and guide strategic decisions. This synergistic methodology, combining the reliability of mainframe metadata with the analytical power of AI, overcomes the limitations of context-free AI, leading to a faster, more accurate, and ultimately more successful modernization trajectory for critical COBOL applications. The accurate and complete data from mainframe metadata fuels reliable AI analysis, while AI boosts efficiency and understanding, creating a powerful synergy that accelerates the evolution of these vital systems.
AI-Driven COBOL Transformation: The AST Foundation
Abstract Syntax Trees (ASTs) provide AI with a structured, semantically rich representation of code, enabling advanced analysis, transformation, and generation. They bridge the gap between raw code and AI understanding, facilitating tasks like bug detection, optimization, and natural language integration.
Generating ASTs from COBOL code provides a structured, machine-interpretable model, crucial for modernizing complex mainframe systems and unlocking the potential of AI-driven transformation. COBOL ASTs transform legacy code into a data-rich format, enabling automated analysis and modernization workflows, while also providing the crucial structured data needed to leverage the power of AI for intelligent and efficient mainframe evolution.
AST based modernization approaches facilitate the following:
- ASTs parse COBOL into a hierarchical structure, clarifying program logic and data dependencies for analysis.
- Data structures, program relationships, and dependencies are extracted, providing a comprehensive application overview.
- ASTs facilitate automated static analysis, identifying code vulnerabilities, compliance issues, and dead code.
- ASTs enable automated refactoring, simplifying code optimization and updating legacy constructs.
- They provide a foundation for automated COBOL to modern language translation, accelerating migration.
- Automated generation of flowcharts, data diagrams, API documentation, and business rule descriptions.
- ASTs automate test case generation and business rule extraction, ensuring code correctness and alignment.
- Accurate ASTs provide the structured data necessary for AI models to understand the semantic meaning of COBOL code.
- AI algorithms can analyze ASTs to automatically comprehend complex COBOL logic, identifying patterns and relationships.
- AI can use ASTs to perform intelligent code transformations, such as automated refactoring based on learned patterns and optimization strategies.
- Machine learning models can be trained on ASTs to extract complex business rules and data dependencies, automating the knowledge discovery process
- ASTs can serve as a foundation for AI-driven code generation, enabling the automatic creation of modern code equivalents from legacy COBOL.
Understanding COBOL – A Divisional Breakdown
We will break down a typical COBOL program into its main divisions and illustrate their relationships.
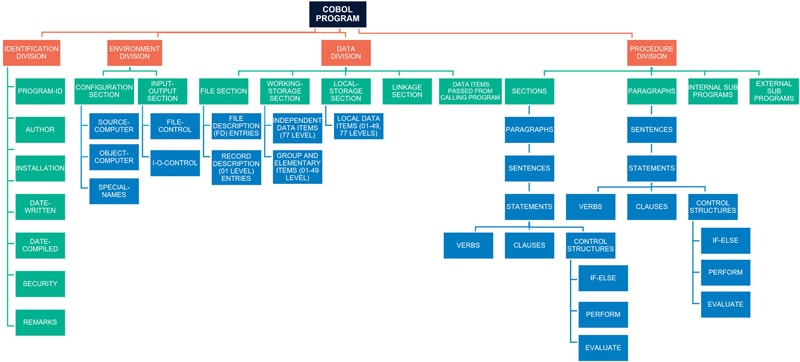
Now, let us examine the high-level AST representation of the COBOL Data Division.
Data Division AST – Structural Elements
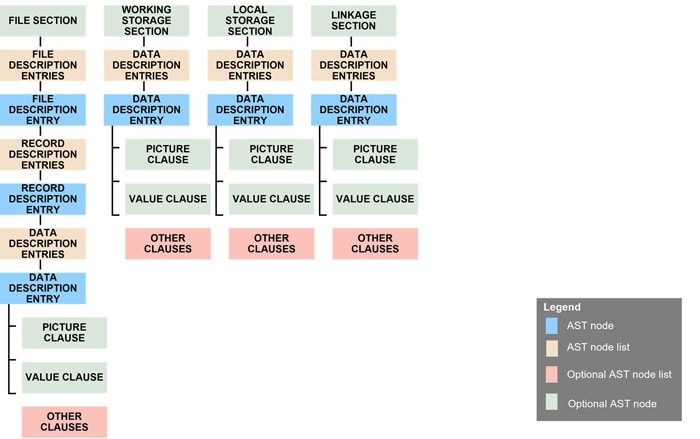
Let us see the high-level AST representation of the COBOL Procedure Division.
Procedure Division AST – Structural Elements
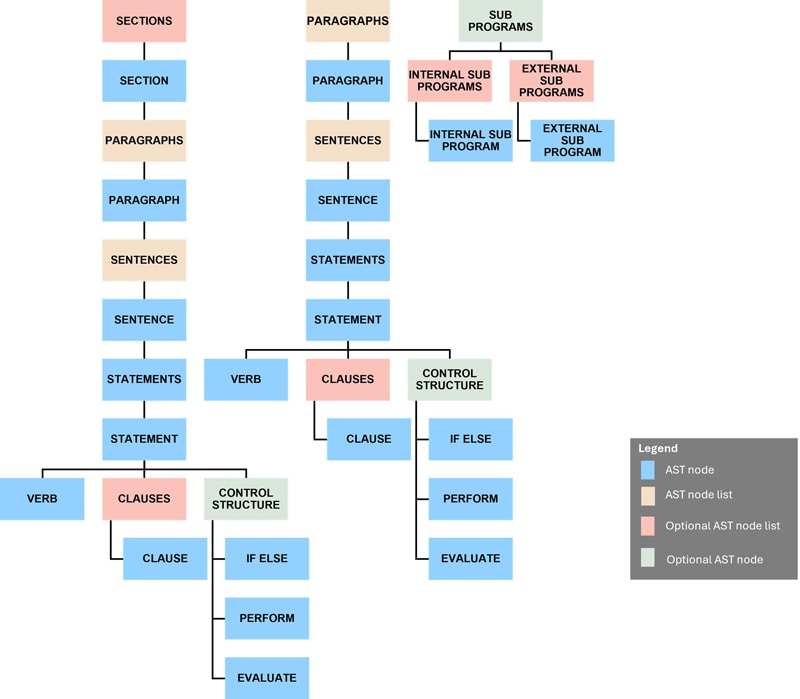
Now, for a combined view, let's analyze a sample COBOL program featuring a variety of verbs and data declarations.
Understanding COBOL Structure: A Representative AST
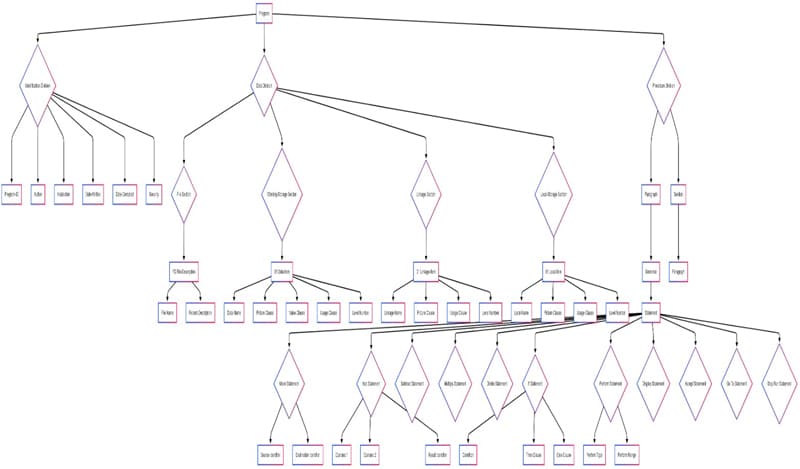
It is evident from the above diagram that visual AST representations significantly enhance comprehension of legacy COBOL, even for those unfamiliar with the language. We will proceed to detail a method for generating highly reliable ASTs, leveraging mainframe metadata for guaranteed precision.
A mainframe-resident, tool-agnostic methodology produces ASTs from COBOL, providing comprehensive metadata for AI/ML training. This facilitates automated analysis (rule extraction, complexity assessment) via Python/Java libraries or advanced AI models (GNNs, Transformers). AST generation is foundational and labelled data and domain expertise are critical for accurate AI-driven insights.
Recommended Method and Its Benefits
The method advocated here leverages one of the COBOL compiler Intermediate Representations (IR) named ADATA, for automated AST generation. Precise, compiler-generated ASTs, unlike error-prone manual parsing, enable AI to accurately analyze complex COBOL structures (E.g.: Copybooks, REDEFINEs). This accuracy feeds AI-powered tools for automated documentation, transformation, and visualization, drastically reducing manual effort. Symbol table data derived from the IR empowers AI to understand data flow and dependencies, critical for generating optimized, modern code.
IBM z/OS COBOL compilation involves several phases:
- Scan Phase (Lexical Analysis): Tokenizes and performs basic syntax checks.
- Syntax Analysis/Parsing: Builds the initial Intermediate Representation (IR), often an Abstract Syntax Tree (AST), representing the code's structure.
- Semantic Analysis: Refines the IR with semantic information (types, symbols), preparing it for code generation.
- Code Generation: Translates the IR into optimized machine code.
- Listing Generation: Creates a compiler listing with source, errors, and diagnostics.
- Object Deck Generation: Produces the machine code object file for linkage.
The IR is built incrementally during parsing and semantic analysis, serving as an abstract, semantically rich representation for code generation.
The COBOL compiler's semantic analysis phase generates ADATA, a binary Intermediate Representation (IR), when the ADATA compiler option is enabled. This variable-length file, structured with IBM-documented record types, was successfully parsed in a proof-of-concept conducted by the author, which demonstrated the extraction of parse trees, tokens, and symbol tables and some additional other record types also from ADATA, validating its potential for automated code analysis and transformation and for reliable AST generation.
The IBM Record Generator for Java provides a relevant example of ADATA's practical application, leveraging its metadata to achieve accurate data type and structure translation between COBOL and Java environments.
These are the record types in the ADATA file:
- Job identification record
- ADATA identification record
- Compilation unit start | end record
- Options record
- External symbol record
- Parse tree record
- Token record
- Source error record
- Source record
- COPY REPLACING record
- Symbol record
- Symbol cross-reference record
- Nested program record
- Library record
- Statistics record
- EVENTS record
It is clear, based on the record types, that ADATA encompasses the entirety of COBOL program information.
Demonstration of the approach
Consider the following COBOL program, which is quite basic:
IDENTIFICATION DIVISION.
PROGRAM-ID. SAMPLE.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC 9(3) VALUE 10.
01 WS-NUM2 PIC 9(3) VALUE 20.
01 WS-RESULT PIC 9(4).
PROCEDURE DIVISION.
MAIN-PROCEDURE.
IF WS-NUM1 < WS-NUM2 THEN
ADD WS-NUM1 TO WS-NUM2 GIVING WS-RESULT
ELSE
SUBTRACT WS-NUM1 FROM WS-NUM2 GIVING WS-RESULT.
DISPLAY 'Result: ' WS-RESULT
STOP RUN.
The following AST diagram, rendered using Mermaid's graph TD directive for top-down visualization, was constructed from the specified syntax (Refer below). Notably, node representations comprised rectangular nodes, denoted by [Labels] (e.g. WS-RESULT, and diamond nodes, denoted by {Label} (e.g., WORKING-STORAGE SECTION). Leveraging ADATA-derived parse tree, symbol, and token files, a comprehensive dataset encompassing node identifiers, labels, and directional edges can be programmatically assembled to generate such AST syntax. While Mermaid served as a demonstrative tool, any suitable visualization platform can be employed. Crucially, the mainframe-sourced metadata eliminates constraints related to program size or complexity, ensuring scalability and accuracy.
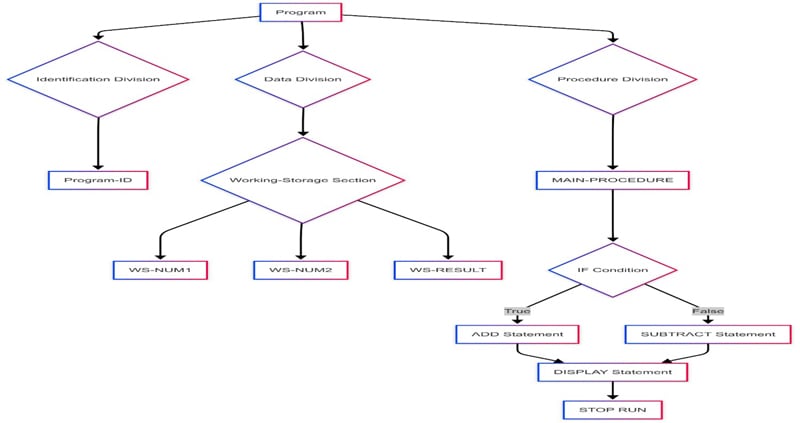
Syntax:
graph TD
A[Program] --> B{Identification Division};
A --> C{Data Division};
A --> D{Procedure Division};
B --> E[Program-ID];
C --> F{Working-Storage Section};
F --> G[WS-NUM1];
F --> H[WS-NUM2];
F --> I[WS-RESULT];
D --> J[MAIN-PROCEDURE];
J --> K{IF Condition};
K -- True --> L[ADD Statement];
K -- False --> M[SUBTRACT Statement];
L --> N[DISPLAY Statement];
M --> N;
N --> O[STOP RUN];
N --> O[STOP RUN];
A proof-of-concept implementation was developed by the author, wherein parsers were constructed for a significant subset of ADATA record types, utilizing IBM-provided record layout specifications. These parsers were developed in COBOL and ReXX language. Any high-level programming language or Assembler can be used for this. These parsers facilitated the extraction of structured artifacts from binary ADATA files, including parse trees, symbol tables, token lists, and auxiliary data structures, which are essential for Abstract Syntax Tree (AST) generation. This investigation demonstrated that a singular parser implementation, derived from the ADATA layout, effectively processes any COBOL program, ensuring comprehensive and accurate data retrieval. Critically, this approach eliminates dependencies on middleware-specific parsing (DB2, CICS, IMS), as ADATA is generated after pre-processing/translation, guaranteeing a uniform COBOL-centric data feed. Furthermore, the translated CALL and MOVE statements, representing embedded EXEC SQL and EXEC CICS commands, provide the necessary attributes for accurate data flow and control flow analysis.
Illuminate the Unknown with the Metadata
Unlocking the rich details within COBOL metadata empowers AI to deliver powerful insights, with the added benefit of generating extensive, structured, and authentic metadata directly from the compiler. This capability paves the way for efficient modernization, reduced risk, improved efficiency, enhanced code quality, better knowledge transfer, and ultimately unlocks business value while lowering legacy system costs. Here is where AI can unlock major potential by using COBOL metadata:
- AI can analyze COBOL metadata (structure, properties) in SQL Server or similar databases for insights. This includes program names, data structures, control flow, etc.
- This would be extremely helpful during modernization, documentation, impact analysis, quality assessment, testing, and portfolio management of COBOL applications.
- AI can employ techniques like NLP, graph analysis, ML, and rule-based systems can be used to process and understand the metadata.
Conclusion
The requirement for program compilation, though a factor to consider across diverse environments, becomes a significant strength where feasible. This process, crucially, does not necessitate a full compilation cycle; object module generation can be bypassed. The resulting reliably generated AST acts as a vital bridge, abstracting underlying business logic from raw COBOL. Its structured format and semantic richness are indispensable for accurate business rule extraction, a cornerstone of successful modernization and documentation. The powerful synergy of mainframe metadata, particularly ADATA, with AI capabilities significantly eases the complexities of COBOL decoding. This enables advanced code analysis, transformation, and generation, accelerating modernization while safeguarding critical business logic. Moreover, this rich metadata empowers AI/ML training and facilitates dynamic chatbot queries for immediate system understanding. Therefore, adopting this metadata-driven AST approach is not merely advantageous but crucial for effectively navigating COBOL modernization in the AI era.
References
Appendix 1- Content summary of ADATA record type for Symbols:
| SYMBOLS |
|---|
| SYMBOL_ID |
| LINE_NUM |
| LEVEL |
| QUALIFICATION_INDICATOR |
| SYMBOL_TYPE |
| SYMBOL_ATTRIBUTE |
| CLAUSES |
| DATA_FLAGS1 |
| DATA_FLAGS2 |
| DATA_FLAGS3 |
| FILE_ORG_ATTRIB |
| USAGE_CLAUSE |
| SIGN_CLAUSE |
| INDICATORS |
| SCALE |
| STORAGE_TYPE |
| DATA_FLAGS6 |
| DATA_FLAGS4 |
| DATA_FLAGS5 |
| BASE_LOCATOR_CELL |
| SYMBOL_IDENTIFIER |
| STRUCTURE_REPLACEMENT |
| PARENT_REPLACEMENT |
| PARENT_ID |
| REDEFINED_ID |
| START_RENAMED_ID |
| END_RENAMED_ID |
| PROGRAM_NAME_SYMBOL_ID |
| OCCURS_MINIMUM_PARAGRAPH_ID |
| OCCURS_MAXIMUM_SECTION_ID |
| DIMENSIONS |
| CASE_BIT_VECTOR |
| DYNAMIC-LENGTH ITEM LIMIT |
| VALUE_PAIRS_COUNT |
| SYMBOL_NAME_LENGTH |
| PICTURE_OR_ASSIGNMENT_DATA_OR_NAME_LENGTH |
| INITIAL_VALUE_LENGTH_FOR_DATA_NAME |
| EXTERNAL_CLASS-NAM_LENGTH_FOR_CLASS-ID |
| ODO_SYMBOL_NAME_ID_OR_ASSIGN_DAT_NAME_ID |
| KEYS_COUNT |
| INDEX_COUNT |
| SYMBOL_NAME |
| PICTURE_DATA_STRING_OR_ASSIGNMENT-NAME |
| INDEX_ID_LIST |
| KEYS |
| INITIAL_VALUE_DATA_OR_EXTERNAL_CLASS_NAME |
Appendix 2 - Content summary of ADATA record type for PARSE TREE
| PARSE_TREE |
|---|
| NODE_NUM |
| NODE_TYPE |
| SUBNODE_TYPE |
| PARENT_NODE_NUM |
| LEFTSIBLING_NODE_NUM |
| SYMBOL_ID |
| FIRSTTOKEN_NUM |
| LASTTOKEN_NUM |
| NODE_INFO |
Appendix 3 - Content summary of ADATA record type for TOKENS
| TOKENS |
|---|
| TOKEN_NUM |
| TOKEN_CODE |
| TOKEN_NAME |
| TOKEN_LENGTH |
| TOKEN_COLUMN |
| TOKEN_LENGTH |
| CONTINUATION_FLAG |
| TOKEN_TEXT |
Appendix 4 - Content summary of ADATA record type for Symbol Cross Reference
| SYMBOL_CROSS_REFERENCE |
|---|
| SYMBOL_NAME_LENGTH |
| STMT_DEFN_LINE_NO_OR_NUMREF |
| SYMBOL_NUM_OF _REFERENCES |
| CROSS-REFERENCE TYPE |
| SYMBOL_NAME |
| SYMBOL_REFERENCE_FLAG |
| SYMBOL_REFERENCE_LINE_NUM |
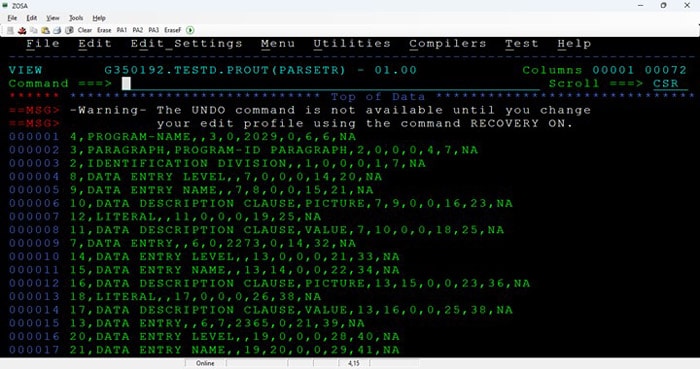
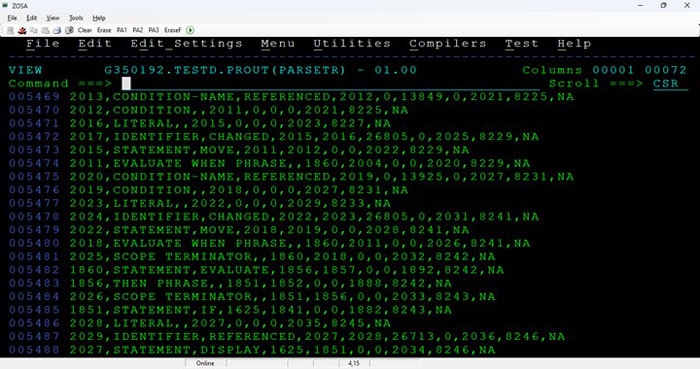
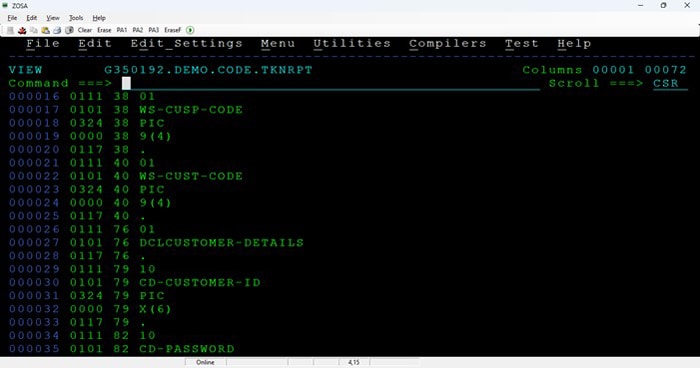
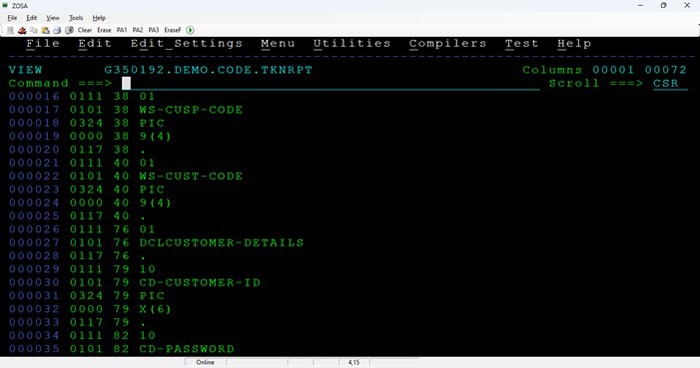
Appendix 5 - Sample Screenshots from the PoC output with compiler sourced metadata:
Parse tree metadata samples
Tokens metadata samples:






Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!