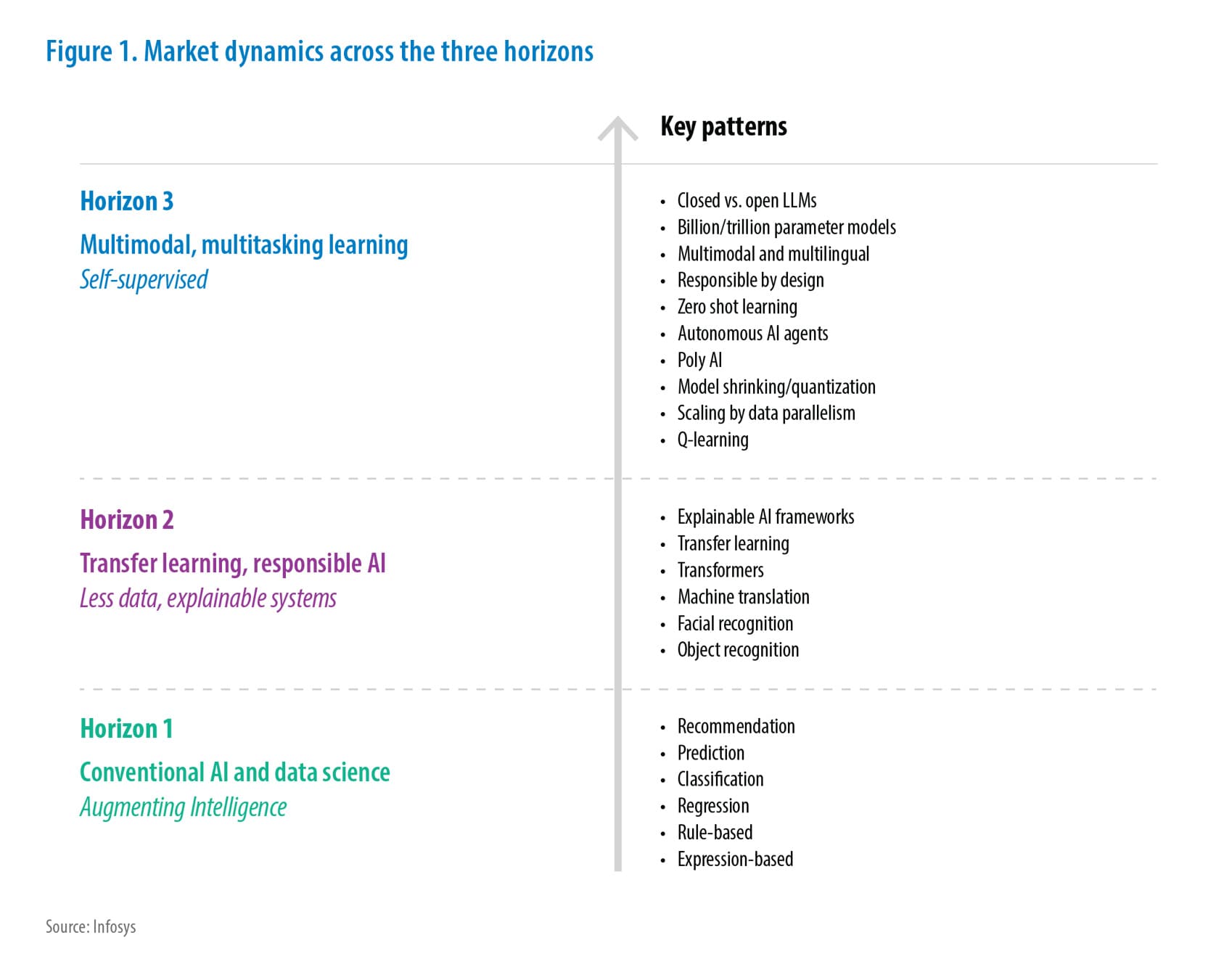
Digital Workplace Services




Bringing Characters to life Azure powered expressive avatars
The demand for engaging empathetic, personalized digital experiences is fueling a rapid rise in digital talking avatars (a.k.a. Digital Human). Driven by GenAI & AI advancements, these avatars humanize digital interactions across customer service, e-learning, and entertainment. Talking avatars add a human touch to digital interactions, making them more engaging and relatable. These Avatars can engage users through natural, dynamic conversations, offering personalized experiences across various applications. Lip-synchronization, the process of matching lip movements with spoken audio, plays a crucial role in the creation of digital avatars. Lip-synchronization is an essential technique for bringing characters to life, ensuring their conversation appears natural and synchronized with their mouth movements. This synchronization not only adds to the realism but also enhances the overall user experience by making interactions with animated characters more appealing and believable. Achieving high-quality lip- synchronization requires complex technology to analyze audio and map it to corresponding visual representations, known as visemes. Beyond Lip-synchronization, facial expressions are needed to add emotional depth to virtual characters. This means not just matching mouth movements to speech, but also conveying emotions like happiness, sadness, or anger. This paper presents end-to-end implementation of a hyper-realistic talking avatar, built entirely with Azure APIs. This solution showcases the power of Azure's speech and animation capabilities to create avatars that not only lip-sync accurately but also convey realistic facial expressions and emotional tones. This enables developers to build personalized, engaging experiences across various platforms, enhancing user interaction and immersion.
Insights
- This white paper explores the creation of hyper-realistic, expressive talking avatars using Azure's AI services.
- The paper details the technical implementation of an avatar system, explaining the use of Azure Cognitive Services for speech synthesis, viseme mapping, emotion detection, and more.
- The white paper discusses the potential applications of these avatars across various industries, including customer service, e-learning, entertainment, and accessibility.
- The paper highlights how realistic lip-synchronization and facial expressions, driven by Azure's AI, enhance user engagement and create more human-like digital interactions.
Introduction
In the current digital era, the demand for engaging and personalized online experiences has increased. Traditional digital interactions, often limited to text and static visuals, can feel impersonal and lack the emotional depth of face-to-face communication. This disconnect creates a significant challenge for businesses and organizations seeking to build meaningful connections with their audiences. Digital avatars, virtual representations of human characters, will revolutionize how we interact with technology. This white paper delves into the creation of highly realistic, expressive talking avatars using the power of Azure’s advanced AI services. We will explore how these avatars, capable of realistic lip-synchronization and a wide range of facial expressions, can bridge the gap between human interaction and digital experience. By leveraging Azure, we aim to demonstrate the potential for building immersive and personalized experiences across diverse applications, from customer service and e-learning to entertainment and accessibility.
The Rise of Digital Avatars
AI-powered speech synthesis, natural language processing, and computer vision have enabled the creation of avatars that can not only speak and listen but also convey emotions and respond dynamically to user input. This technological leap has opened a plethora of opportunities across various industries.
Customer Service: Digital avatars, acting as virtual assistants, can provide personalized and engaging support, handling routine inquiries and freeing up human agents for more complex tasks. By acting as virtual assistants, they offer 24/7 availability, consistent service quality, and the ability to handle a high volume of inquiries simultaneously.
E-learning: Digital avatars can serve as interactive tutors, guiding students through lessons and providing personalized feedback, significantly enhancing information retention and engagement. Avatars can also create immersive learning environments, simulating real-world scenarios and allowing students to practice skills in a safe and controlled setting. For example, a medical student could practice patient interactions with a virtual avatar, gaining valuable experience without the risks associated with real-life scenarios.
Entertainment Industry: Digital avatars are transforming gaming and virtual events, creating immersive experiences that blur the lines between reality and simulation. In gaming, avatars are becoming increasingly realistic, blurring the lines between virtual and real worlds. Virtual events, such as concerts and conferences, are also being transformed by avatars, allowing participants to interact with each other and the performers in a virtual space. This creates a sense of presence and connection that is often lacking in traditional online events.
Accessibility and Inclusive Communication: Digital avatars are proving to be invaluable tools for enhancing accessibility for individuals with disabilities by providing visual cues and alternative communication channels that can significantly improve their digital interactions.
Benefits of Digital Avatars
Enhanced User Engagement: Digital avatars make online interactions feel more human, which helps people connect better and remember the experience. The lively expressions and natural conversations of avatars keep users interested and significantly increase engagement.
Personalized Experiences: Avatars can change to match what each person likes, creating custom experiences that fit their specific needs and interests. You can change things like the avatar's voice, how it looks, and how it talks to you, which makes the experience very personal.
Improved Accessibility: Avatars offer important ways to communicate through visuals and interaction, helping people with different needs access digital content more easily. They use things like visual cues, sign language, and text-to-speech, which helps people who have trouble with regular means of communication.
24/7 Availability and Scalability: Because avatars are available 24/7, they can give constant support and information without any breaks. Plus, they can handle many conversations at once, which makes them perfect for situations where you need to serve a lot of people at the same time.
As remote communication becomes increasingly prevalent, the ability to create engaging and lifelike digital representations is no longer a luxury but a necessity. The evolution of digital avatars marks a fundamental change in how people engage with digital environments. With Azure capabilities, these virtual characters can be developed into more interactive and lifelike interfaces, enabling richer and more natural user experiences.
The Importance of Realistic Avatar Behaviour
Realism is paramount in effective avatar communication because it bridges the gap between digital interaction and human connection. When avatars exhibit lifelike behaviors, they foster trust and engagement, making users feel more comfortable and receptive. When avatars act like real people, we trust them more and pay attention. We feel more comfortable and interested. Because we naturally notice small changes in faces and body language, realistic avatars feel believable. They can even make us feel real emotions, just like talking to a person, which makes the whole experience better. A realistic avatar can evoke emotional responses like those expressed by human interaction, creating a sense of presence and connection that enhances the user experience.
Lip-Synchronization: A Key Component of Realism
Achieving accurate lip-synchronization is a significant technical challenge due to the complexity of human speech. It requires precise analysis of audio waveforms and mapping them to corresponding mouth movements. Visemes, the visual representations of phonemes (basic units of sound), play a crucial role in this process. By accurately matching visemes to spoken audio, we can create the illusion of natural speech. The impact of accurate lip-sync on user perception is substantial. When lip movements are synchronized with speech, users perceive the avatar as more intelligent and engaging. Conversely, even slight discrepancies can disrupt the illusion, leading to a sense of unease and diminished engagement.
Facial Expressions and Emotional Nuance
Facial expressions are fundamental to human communication, conveying emotions and adding depth to verbal messages. Avatars that can accurately replicate a wide range of facial expressions are better equipped to engage users and convey emotional nuance. Capturing and replicating subtle emotional cues, such as micro-expressions and subtle shifts in gaze, is crucial for creating realistic and believable avatars. These cues provide context and enrich communication, enabling avatars to convey complex emotions like empathy, enthusiasm, and concern. Conversely, the lack of emotional expression can create an "uncanny valley" effect, where users experience a sense of unease and discomfort. This phenomenon occurs when avatars appear almost human but lack the subtle nuances that make human faces expressive. The result is a feeling of artificiality and detachment, hindering effective communication and engagement. By focusing on realism in lip-synchronization and facial expressions, we can create avatars that feel genuinely human, fostering meaningful connections and enhancing the overall user experience.
Azure's Role in Building Expressive Avatars
Azure, Microsoft's cloud platform, provides a comprehensive suite of tools that are important for creating realistic lip-sync in digital avatars. Using Azure Cognitive Services, developers can leverage advanced speech recognition and facial animation technologies to automate the lip-synchronization process. Azure Speech Services converts spoken audio into a precise sequence of visemes. These visemes, essentially the visual representations of phonemes—the smallest, distinct units of sound that make up speech—serve as the crucial link between audio and visual animation. By accurately extracting and mapping these visemes, Azure enables developers to generate highly synchronized lip movements for digital avatars, ensuring a natural and engaging user experience. This robust pipeline, powered by Azure's AI, not only streamlines the animation process but also significantly enhances the realism and emotional expressiveness of digital avatars, bridging the gap between digital and human interaction.
Understanding Visemes
Visemes are the visual representations of phonemes, the smallest units of sound that distinguish one word from another in a language. Unlike phonemes, which are auditory, visemes are the corresponding mouth shapes and movements observed when a person speaks. Effectively, a viseme is the visual equivalent of a phoneme. Since multiple phonemes can sometimes produce similar mouth shapes, the number of visemes is typically smaller than the number of phonemes in a language. Accurately mapping audio to visemes involves analyzing speech patterns and correlating them with specific mouth formations. This process is crucial for creating the illusion of natural speech in avatars. When an avatar's lip movements precisely match the spoken audio through accurate viseme implementation, it significantly enhances the user's perception of realism, contributing to a more engaging and believable digital interaction.
Figure 1: Visual representations of Viseme Left to Right: Viseme O, Viseme P, Viseme A, Viseme S
![]()
Azure Speech Service provides powerful tools for converting audio input into visemes. This process involves analyzing the audio to identify phonemes and then mapping these phonemes to their corresponding visemes. By leveraging Azure's advanced speech recognition capabilities, developers can automate this conversion and generate precise lip-synchronization. Understanding the viseme data generated by the audio analysis is key to creating lifelike avatar speech. The system produces a sequence of viseme events, each detailing when and how a specific mouth shape occurs. Here's a breakdown of the information provided:
Viseme ID: A number that represents a specific mouth shape
Timestamp: The exact moment in the audio when that mouth shape appears.
Duration: How long that mouth shape is held.
![]()
This data allows you to synchronize an avatar's mouth movements with its speech. Each viseme ID is linked to a particular mouth position, which can be applied to a 3D model's animation. By timing these mouth shapes correctly, you can create smooth and natural lip-sync.
Azure Speech Service streamlines this complex process, providing developers with the necessary tools to easily add realistic lip-sync to their projects.
Enhancing Expressiveness Beyond Lip-Sync: Utilizing Blend Weights
Azure's viseme analysis provides a highly detailed output, going beyond simple mouth shape data. When Azure analyzes speech, it doesn't just tell us mouth shapes. It gives us detailed instructions on how the entire face should move, broken down into tiny steps called frames. These frames are grouped together to match the audio perfectly. Each frame contains 55 numbers, which tell the 3D avatar how to move its face—things like eyebrows, eyes, cheeks, and mouth. Application logic plays these frames right before the matching sound, so the face moves exactly with the speech. This detailed information lets us create very realistic facial expressions that make our avatars feel alive. Sample output of Blend shape weights:
{
"FrameIndex":0,
"BlendShapes":[
[0.021,0.321,...,0.258],
[0.045,0.234,...,0.288],
...
]
}
Figure 2: A few Realistic Expressions Left to Right: surprise, happy
![]()
Technical Implementation: Building the Avatar
This section delves into the technical architecture and data flow of our Azure-powered expressive avatar system. The diagram below illustrates the end-to-end process, showcasing how user input is transformed into a dynamic and engaging avatar experience. It highlights the integration of various Azure Cognitive Services and our Avatar Backend, demonstrating the intricate orchestration of AI-driven components to achieve realistic speech, facial expressions, and emotional conveyance.
Figure 3: Reference Architecture for Avatar based virtual assistant
![]()
User Input: Users interact with the system through a 'Chat interface + Avatar Display' and 'Video Feed' within a browser. They can provide either 'Audio/Text' queries or a 'Video Feed.'
Language Processing: If the user provides audio input, the system first identifies the language using 'Azure Language Identification' and then converts the speech to text using 'Azure STT' (Speech-to-Text).
Conversational AI: The user's text query, or the text generated by Azure STT, is sent to 'Azure OpenAI conversational Bot' to generate a contextually relevant 'Response Text.'
Core Backend Processing: The 'Avatar Backend' acts as the central hub, managing the 'Avatar Generation Module.' This module orchestrates the flow of data and integrates the various Azure services.
Speech Synthesis and Viseme Generation: The 'Response Text' is processed by 'Azure TTS' (Text-to-Speech) to generate 'Response Audio.' Simultaneously, 'Azure Viseme' generates 'Viseme' data, which represents the visual lip movements corresponding to the speech.
Emotion and Sentiment Analysis: The 'Response Text' is also analyzed by 'Azure Sentiment Analysis' to determine the sentiment of the response. The 'Video Feed' is processed by 'Azure Emotion Detection' to extract emotional cues from the user's facial expressions.
Avatar Display: The 'Response Audio,' 'Viseme' data, and emotional cues are combined within the 'Avatar Backend' to drive the avatar's display. The avatar's facial expressions and lip movements are synchronized with the audio, creating a realistic and engaging interaction.
Data Flow: The arrows in the diagram illustrate the flow of data between the various modules, showcasing the interconnectedness of the system.
This architecture demonstrates the power of Azure's AI services in creating highly expressive and interactive avatars. By combining speech recognition, natural language processing, emotion analysis, and real-time animation, we can develop avatar experiences that are both engaging and informative.
Facial Expression and Animation Techniques
1. Avatar Model Integration and Blend Shape Mapping
Our avatar system supports a range of 3D avatar models, including highly realistic characters created with tools like Character Creator, as well as stylized cartoon avatars from platforms such as Ready Player Me. These models are designed with comprehensive blend shape capabilities, allowing for detailed facial animations. A critical step in our process is establishing a precise mapping between the blend shapes of our chosen avatar and the viseme data provided by Azure. This mapping ensures accurate lip synchronization, where the avatar's mouth movements perfectly align with the spoken audio. By correlating Azure's viseme outputs with the corresponding blend shapes within the 3D model, we achieve a natural and engaging speech animation.
2. Facial Expressions Driven by Azure Viseme Blend Weights
Beyond lip-sync, Azure's Viseme API provides a rich set of 55 blend weights, each corresponding to various facial blend shapes. These blend weights enable us to generate a wide array of facial expressions, including eyebrow movements, eye blinks, cheek raises, and subtle emotional cues. We apply these blend weights directly to the corresponding blend shapes of our avatar's face, allowing for nuanced and dynamic facial expressions. This integration of Azure's blend weight data with our avatar's facial rig ensures that the expressions are synchronized with the audio and context of the interaction, enhancing the avatar's realism and emotional depth.
3. Dynamic Animation for Enhanced Realism
To further imbue our avatars with a sense of life and personality, we incorporate dynamic animations that go beyond basic lip-sync and facial expressions. These animations, such as subtle breathing patterns, natural head movements during speech, and contextual gestures (e.g., happy gestures during positive interactions), add a layer of realism and engagement. We employ a runtime animation system, where animations are dynamically triggered and blended based on the situation. For instance, a cheerful tone from the Azure OpenAI conversation bot might trigger a 'happy gesture' animation, while periods of silence might trigger a 'breathing' animation. This dynamic animation approach ensures that the avatar's behavior is contextually relevant and engaging, creating a more immersive and believable interaction.
Conclusion
In this paper, we have presented a comprehensive overview of our Azure-powered expressive avatar system, a culmination of cutting-edge AI technologies designed to humanize digital interactions. As demonstrated in the preceding diagram, our system leverages the robust capabilities of Azure Cognitive Services, including Azure OpenAI, Azure Speech-to-Text (STT), Azure Text-to-Speech (TTS), Azure Viseme, Azure Sentiment Analysis, and Azure Emotion Detection, to create highly realistic and engaging avatars.
By combining these powerful Azure services, we have created an avatar system that transcends simple text-to-speech, enabling avatars to understand, respond, and express emotions with remarkable fidelity. This system has the potential to transform various industries, as discussed in the "Rise of digital avatars" section, by creating more engaging and personalized digital experiences.
References
- "Virtual Human: A Comprehensive Survey on Academic and Applications" - Thiebaut, R., Bailly, G., & Elisei,F.
- “Expressive Avatars: Vitality in Virtual Worlds" - Ekdahl, David & Osler, Lucy.
- "How to Integrate Azure Speech-to-Text and Viseme Generation for Realistic Lip Syncing in Virtual Environments" - Owens, Cheryl & Alwabel, Rakan
- "Unlocking the Power of Azure: Audio to Viseme Conversion Explained"- Muhammad, Yusuf & Alwabel, Rakan
- "OUTCOME Virtual: a tool for automatically creating virtual character animations' from human videos"- Auriane Boudin, Ivan Derban, Alexandre D'Ambra, Jean-Marie Pergandi, Philippe Blache, Magalie Ochs.
- "Microsoft Azure Cognitive Services Documentation"- Microsoft
Acknowledgements
We would like to acknowledge the invaluable support and contributions of several individuals who were instrumental in the successful completion of this work, conducted under the New Interaction Model, Applied Research Center. We extend our sincere appreciation to Aditya Yelgawakar, Harshal Kolambe, Vikas Ashok Varthak, Sean Paul Marr, Maurice Go and Sunil Mukherjee for their dedicated efforts and engagement throughout the various stages of this research. Their contributions were integral to the development and execution of this project.
Furthermore, we would like to express our gratitude to Vishwa Ranjan for his insightful review and constructive feedback. His valuable input significantly enhanced the quality and rigor of this paper.






Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!