Cloud




Cloud Resiliency in Modern Computing
This point of view outlines how organizations can leverage cloud platforms to strengthen resiliency, safeguard data, maintain operational continuity, and ensure compliance.
Insights
- Understand the core principles of Cloud Resiliency
- Business Benefits of Cloud Resiliency
- Cloud Resiliency Best Practices
Introduction
In today’s fast-paced digital world, businesses rely heavily on cloud computing to streamline operations, enhance scalability, and improve overall efficiency. With cloud adoption accelerating and systems becoming more distributed, the frequency and impact of disruptions, whether caused by misconfigurations, cyberattacks, provider issues, or natural events have increased. Cloud resiliency ensures continuity by preventing outages where possible, reducing their impact when they occur, and restoring normal operations efficiently.
Cloud Resiliency in Ever-Changing Landscape
What is Cloud Resiliency?
Cloud resiliency is the ability of a workload to protect against disruptions, minimize their impact, and recover quickly from infrastructure or service failures. It encompasses proactive measures to safeguard data and operations, dynamic resource allocation to maintain performance, and automated mechanisms to mitigate issues such as misconfigurations, cyber threats, or transient network problems. For example, when a primary region becomes unavailable, workloads should automatically fail over to a secondary region without manual intervention.
Why Cloud Resiliency matters?
Downtime and data loss lead to revenue impact, reputational damage, and regulatory risk. Resilient design minimizes these risks by keeping services available and accessible data during disruptions, and by enabling rapid recovery aligned to business objectives.
For example, if there is a power outage at a data center, a resilient cloud system would automatically switch to an alternative data center, ensuring that applications and data remain available to users without any interruption.
Another advantage of cloud resiliency is that it helps to reduce recovery time in case of disruptions. Instead of spending time and resources on restoring data and systems, a resilient cloud system can quickly recover from failures and resume operations.
In addition, it can also help businesses to comply with regulatory requirements related to data availability and disaster recovery.
Core principles of Cloud Resiliency
The core principles of cloud resiliency define the strategies and mechanisms that enable workloads to remain available, fault-tolerant, and recoverable even during unexpected disruptions.
Cloud resiliency is a critical capability for ensuring uninterrupted operations and rapid recovery in the event of disruption. The framework consists of three foundational pillars:
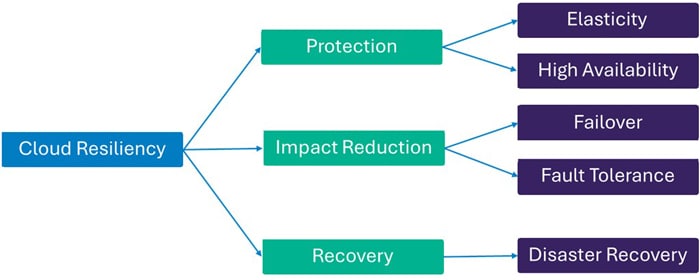
- Protection: Implements proactive measures such as elasticity, high availability to prevent outages and maintain service continuity.
- Impact Reduction: Focuses on failovers and fault tolerance, enabling systems to continue functioning even when individual components fail.
- Recovery: Emphasizes disaster recovery strategies to restore operations quickly after major incidents.
Together, these elements form a comprehensive approach to safeguarding business continuity, minimizing downtime, and strengthening overall system reliability in cloud environments.
Presented below is the list of key principles of Cloud Resiliency:
- Elasticity refers to the ability to dynamically match capacity to demand to sustain performance during spikes or drops.
- High Availability refers to architecting across multiple Availability Zones/regions with health checks and load balancing for continuous up time.
- Failover refers to seamlessly redirecting workloads to healthy systems without manual steps.
- Fault Tolerance refers to continuing operating despite component failures via redundancy and self-healing.
- Disaster Recovery refers to rapidly restoring service using backups, cross-region replication, and defined RTO/RPO.
Cloud Resiliency: An End‑to‑End Thread Across the Enterprise
Cloud resiliency is built through a cohesive end‑to‑end thread—from business processes to architecture and design, through implementation, and into operations.
Business Processes:
- Customer experience – Main & alternate paths, core & ancillary services
- Process stability – Online and offline models, integrity, recovery methods across entities
- Operations – Ability to execute from alternate locations, sovereignty needs
- Data Integrity – Common taxonomy, source of truth, reconciliation
Architecture & Design
- Architecture & Design patterns - NFR fulfillment, resource usage, cost
- Tolerance - Recovering for partial failures, partition tolerance, store & forward
- Build & Deploy – vulnerability scan, software supply chain, non-disruptive deployments
- Security – MFA, Zero trust architecture, telemetry, identification and response
Shared Responsibility Model for Resiliency
Cloud Resiliency encompasses a set of strategies, technologies, and best practices designed to minimize downtime, ensure data integrity, and maintain uninterrupted service delivery in the cloud environment.
Cloud resiliency is part of the Reliability pillar for cloud providers and it’s a shared responsibility model:
- The cloud provider is responsible for delivering resilient infrastructure (compute, storage, networking, data center operations).
- The customers select services and build resilient architectures (multi-AZ/region, backups, replication, configuration hardening) to meet business objectives.
Key Components of Cloud Resiliency
Because the goal of cloud resiliency is to keep downtime and data loss to a minimum, the components of cloud resiliency should all contribute to that goal:
- Redundancy
This involves replicating critical components of a system, such as servers, databases, and storage, across multiple geographic locations or availability zones. By having redundant resources in place, organizations can mitigate the impact of failures in one area and ensure continuous availability of services. - Auto Scaling
Cloud environments allow organizations to scale resources up or down based on demand fluctuations, ensuring optimal performance and resource utilization. This flexibility enables businesses to adapt to changing workload requirements and maintain resilience during peak usage periods. - Backup & Recovery
Regularly backing up data to secure off-site locations ensures that critical information remains accessible in the event of data loss or corruption. Disaster recovery plans outline procedures for restoring services quickly and efficiently following a disruptive event. - Monitoring
Automated monitoring tools continuously track the performance and health of cloud resources, detect anomalies or potential issues, and trigger automated recovery processes. This proactive approach minimizes human intervention, reduces response times, and improves overall system reliability.
Measuring Cloud Resiliency: KPIs
| Principle | KPI |
|---|---|
| Elasticity | Scaling Rate: Speed and efficiency with which a system expands or contracts its resource capacity in response to sudden changes in workload. It determines how long a system remains in a degraded state before it can return to its target performance level. |
| High Availability | Uptime: It is the historical record of infrastructure health and is represented by the time it remains operational without crashing or rebooting. Target availability is the specific level of reliability a business intends to provide for its users and considers performance, error rates and ability of a user to complete a task. For example, 99.9%: |
| Failover | Failover latency: It is the total time that elapses from the moment a primary system component fails until a redundant backup system has fully taken over and is successfully processing traffic. For a system to be considered resilient, its failover latency must always be significantly lower than its RTO. |
| Fault Tolerance | Failover Success rate: It is the percentage of failover attempts that are complete without service disruption. Node/Zone failure impact: It is defined as the percentage of workloads that remain operational during a single node or zone outage. |
| Disaster Recovery | Recovery Time Objective (RTO): Maximum acceptable time to restore service after a disruption. Recovery Point Objective (RPO): Maximum acceptable data loss measured by time between last good backup/replica and incident. Mean Time to Recover (MTTR): Average time to restore normal service/operations after an incident and reflect operational efficiency and automation maturity. |
Benefits of Cloud Resiliency
Organizations increasingly rely on cloud platforms to deliver mission-critical services. Any disruption—whether caused by infrastructure failure, cyberattacks, or natural disasters, can lead to significant financial losses and reputational damage. A resilient cloud architecture ensures that businesses can withstand these disruptions, minimize impact, and recover quickly.
| Benefits from a Chief Marketing Officer (CMO) Lens | |||||
|---|---|---|---|---|---|
| Protecting Brand Reputation Demonstrating reliability and continuity. Outages often make headlines and erode customer confidence. A resilient cloud infrastructure demonstrates reliability and commitment to service continuity, safeguarding brand equity and reducing the risk of negative publicity. |
Driving Customer Satisfaction Ensuring consistent performance and rapid recovery. Customers expect uninterrupted access to services. Resilience ensures consistent performance and rapid recovery, leading to improved satisfaction scores and stronger trust in the brand. |
Enhancing Customer Retention Reducing churn by minimizing disruptions and safeguarding data integrity. This ensures businesses foster loyalty and reduces the likelihood of customers switching to competitors. |
|||
| Benefits from a Chief Financial Officer (CFO) Lens | Benefits from a Chief Operating Officer (COO) Lens | Benefits from a Chief Growth Officer (CGO) Lens | |||
| Safeguarding Revenue Streams Avoiding lost transactions for e‑commerce/ financial/ SaaS services. Resiliency ensures continuous service availability, preventing lost transactions and revenue leakage. |
Ensuring Regulatory Compliance Meeting strict up time and data protection obligations. Many industries require strict uptime and data protection standards (e.g., GDPR, HIPAA). Resilient architecture helps meet compliance requirements, avoiding penalties and legal risks. |
Enabling Scalability for Growth Scaling to new markets and seasonal peaks without compromising reliability. Resilient cloud systems can scale seamlessly for growth. |
|||
Case Study: Cloudflare’s Outage – Lessons for Resiliency
Cloudflare experienced a global outage lasting around 3.5 hours due to an overly large automatically generated configuration file, disrupting major platforms.
Forrester highlights this as a critical reminder of the dangers of single-provider reliance, urging enterprises to adopt cloud resilience strategies such as multi-CDN architectures, failover DNS, enhanced observability, zero-trust segmentation, chaos engineering, vendor risk assessments, and resilience-focused contracting.
Key takeaways:
- Avoid single‑provider/centralized control‑plane dependencies, design for fault isolation.
- Test failover under real conditions; rehearse runbooks.
- Adopt multi‑CDN and resilient DNS; improve observability for faster root‑cause analysis.
- Implement architectural decoupling and graceful degradation to contain blast radius.
The Forrester blog on Cloudflare’s outage highlights critical lessons for cloud resiliency that directly relate to the Resiliency principles discussed above. Here’s the mapping with the resiliency principles:
| Principle | Mapping |
|---|---|
| Elasticity | Elasticity must be paired with robust failover and redundancy; reallocate resources during failures, not only traffic spikes. |
| High Availability | Design for multi‑region/multi‑zone to avoid cascading failures from centralized components. |
| Failover | Ensure immediate, seamless failover to unaffected regions; test regularly. |
| Fault Tolerance | Isolate faults so one failure does not propagate; use decoupling and graceful degradation. |
| Disaster Recovery | Predefine RTO/RPO and automate recovery workflows; conduct regular DR drills and distribute control planes. |
Cloud Resiliency Best Practices
When trying to achieve cloud resiliency, businesses should follow these best practices:
| Best Practice | Description |
|---|---|
| Design |
|
| Operations |
|
| Governance and Risk |
|
| Testing and Validation |
|
| Budgeting |
|
Emerging Trends
| Pillars | Trend Description |
|---|---|
| Protection |
|
| Impact Reduction |
|
| Recovery |
|
Conclusion
Cloud resiliency is a critical component of business continuity. By designing fault tolerance, failover and recovery, measuring with clear KPIs, integrating security, and validating via regular testing, organizations can withstand disruptions, minimize impact, and recover quickly while scaling for growth.
References
Appendix – Cloud Resiliency Assessment Scorecard Template
Cloud Resiliency Scorecard
Use this scorecard to assess workload resiliency maturity using a weighted 0–4 scoring model.
| Workload / Program | Owner | Review Date | Environment |
|---|---|---|---|
| Final Score (0–4) | REAL Level | RAG Status |
|---|---|---|
| REAL0 / REAL1 / REAL2 / REAL3 / REAL4 | 🟢 / 🟡 / 🔴 |
Formula: Final Score = Σ (Weighted Scores of All Resiliency Objective)
Score each objective 0–4 (0=No capability … 4=Full capability).
| Element | RES‑# | Resiliency Objective | Weight | Score (0–4) | Evidence / Notes (links to artifacts) |
|---|---|---|---|---|---|
| Design & Architecture | RES‑1 | Fault isolation (Multi‑AZ/Region architecture) | 12% | ||
| Design & Architecture | RES‑2 | Graceful degradation (Dependency hardening) | 8% | ||
| Design & Architecture | RES‑3 | Capacity assurance (Service quotas, limits) | 8% | ||
| Design & Architecture | RES‑4 | Business continuity framework alignment | 12% | ||
| Operational Readiness | RES‑5 | Policy coverage (RTO/RPO by disruption type) | 7% | ||
| Operational Readiness | RES‑6 | SOPs coverage (alarms, runbooks) | 10% | ||
| Operational Readiness | RES‑7 | Contingency planning | 10% | ||
| Operational Readiness | RES‑8 | Tested recovery (chaos & drills) | 8% | ||
| Outcome Reliability | RES‑9 | SLO attainment & error budget burn | 12% | ||
| Outcome Reliability | RES‑10 | Change safety (DORA metrics) | 8% | ||
| Outcome Reliability | RES‑11 | Security score | 5% |
Scoring guidance: 0=None, 1=Minimal, 2=Partial, 3=Strong, 4=Full capability (no critical dependencies).
RAG suggestion (optional): 🟢 ≥3.0, 🟡 2.0–2.99, 🔴 <2.0 (adjust to your risk appetite).
Attach evidence: architecture diagrams (IaC), Well‑Architected findings, runbooks/SOPs, DR drill reports, chaos test results, SLO dashboards, DORA trends, security baseline reports.






Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!