Artificial Intelligence




Comparing Schema Retrieval Methods for Efficient Text to SQL Generation
This white paper presents a comparative evaluation of three schema retrieval strategies: brute-force prompting, a custom dot product-based scoring method, and FAISS-based semantic similarity search, for optimizing large language model (LLM)-driven SQL generation. By reducing prompt size and selectively retrieving relevant schema context, the paper demonstrates measurable gains in efficiency, cost savings, and latency reduction. The solution is implemented in a C# backend using Azure OpenAI and validated using the Sakila database schema.
Insights
- This white paper compares three schema retrieval strategies for text-to-SQL generation: brute-force prompting, a custom dot product similarity method, and FAISS-based semantic retrieval.
- The brute-force method provides full schema coverage but leads to high token usage, latency, and cost, making it unsuitable for scalable systems.
- The dot product method uses statistical filters for lightweight, infrastructure-free schema selection, balancing efficiency with simplicity.
- The FAISS-based method delivers the best performance and cost savings, using vector similarity search with elbow-point filtering to adaptively select relevant schema elements.
- All methods are implemented in a unified C# backend with Azure OpenAI, and tested using realistic prompts over the Sakila database, demonstrating how retrieval-aware design can significantly improve LLM efficiency and scalability.
Introduction
As large language models (LLMs) become more powerful and accessible, their use in natural language interfaces to structured data, such as SQL databases, has expanded rapidly. A core technical challenge in these systems is schema retrieval: how to provide the LLM with only the relevant portion of a database schema so it can generate accurate, efficient SQL queries.
Database schemas in enterprise environments can be vast, often containing dozens of tables. Providing the entire schema in every prompt, while simple, leads to token inefficiency, higher latency, and increased cost. Moreover, excessive context may reduce model precision by introducing noise.
This white paper focuses on evaluating schema retrieval strategies: techniques for selecting the most relevant tables and columns from a schema based on the user’s query. While text-to-SQL generation is used as the target application, the insights and comparisons apply broadly to any LLM-based system that relies on dynamic context selection.
We compare three schema retrieval methods:
- Brute-force prompting: the full schema is included for every query.
- Dot Product scoring: a custom statistical similarity method using vector math and heuristics.
- FAISS-based semantic search: vector embedding retrieval using cosine similarity and approximate nearest neighbors.
Problem Statement
Modern LLM-based systems that generate SQL from natural language rely heavily on having access to relevant database schema information. However, as schemas grow in size and complexity, identifying which parts of the schema to include in the prompt becomes a critical design challenge.
Including the entire schema in every prompt, while simple, results in:
- Excessive token usage, leading to higher API costs
- Increased latency, due to larger prompt size and longer model processing times
- Lower accuracy, as irrelevant schema elements may distract or confuse the model
While some solutions use simple heuristics or keyword matching to reduce context size, these methods often lack semantic understanding and struggle with synonyms or loosely phrased queries.
This paper investigates the problem of schema retrieval: how to dynamically and intelligently select only the most relevant parts of a database schema based on the user query. We explore and compare three different approaches and evaluate them through the lens of a practical application: text-to-SQL generation.
Existing Solutions and Related Work
Numerous text-to-SQL systems and natural language database interfaces have emerged in recent years, especially with the advent of large language models like GPT-3 and GPT-4. While many of these systems focus on prompt design and few-shot learning to improve SQL generation, fewer address the challenge of schema overload directly.
A common baseline approach is to include the entire database schema — table names, column names, and foreign key relationships — in the prompt. This ensures the LLM has full visibility but comes with significant drawbacks: excessive token consumption, slower performance, and potential confusion from irrelevant schema components.
More recent frameworks, such as those built using LangChain SQL agents, attempt to improve query accuracy and reasoning through agent-based orchestration. These agents break tasks into subtasks like schema lookup, query planning, and execution. However, they often still rely on full-schema context or use basic retrieval methods, which can be inefficient and fragile at scale.
Some solutions incorporate vector databases (e.g., Pinecone, Weaviate, Milvus) to enable semantic search over unstructured documents or code and have started to apply these to schema retrieval as well. These tools offer metadata filtering, distributed search, and scalability—but may introduce unnecessary complexity and infrastructure overhead for smaller, structured use cases like schema filtering.
Our work focuses on comparing lightweight yet effective retrieval strategies that can be implemented without the overhead of distributed systems or managed services. By evaluating brute-force inclusion, a custom statistical scoring method, and FAISS-based semantic similarity search, we aim to identify the most practical and scalable approach for optimizing LLM-based SQL generation pipelines.
System Architecture
The architecture of the proposed system is designed to retrieve only the most relevant portions of a database schema in response to a user’s natural language query. This enables efficient and accurate SQL generation using large language models (LLMs) while significantly reducing token overhead. The system is composed of modular components, implemented in a C# backend and integrated with Azure OpenAI services.
Figure 1: Detailed Flow
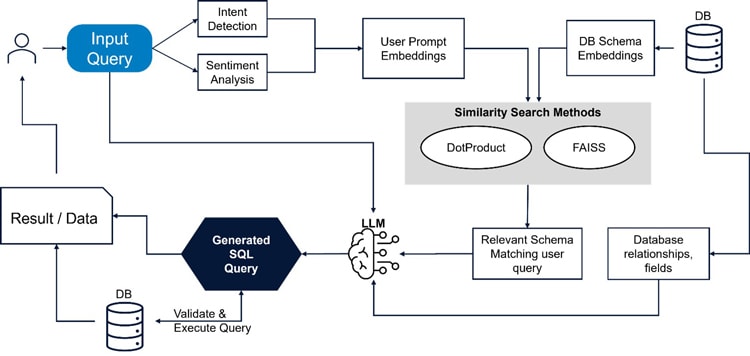
1. Input Processing and Safety Layer
Intent Detection: Upon receiving a natural language query, the system uses a GPT-based model to extract the user’s intent and identify relevant business or attribute keywords. These keywords are converted into embeddings using the OpenAI Ada model.
Sentiment Analysis: A separate check ensures the query is read-only (SELECT). If the model detects the intent to perform DDL or DML operations (INSERT, DELETE, etc.), the system blocks execution and notifies the user.
2. Schema Embedding Store
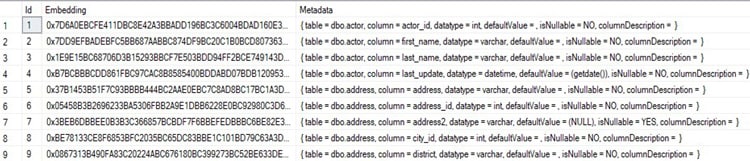
Database schema components (table names, column names, data types, nullability, default values, and descriptions) are flattened into metadata text. This metadata is embedded using OpenAI Ada and stored in a SQL database as byte arrays, along with associated metadata identifiers. These schema embeddings are generated once and reused across queries.
Figure 2: Visualization of Embedding Store
3. Similarity Search Mechanisms
To retrieve relevant schema elements, the system supports three retrieval modes:
Brute Force (Baseline): No filtering; the entire schema is appended to the prompt. Useful as a baseline for comparison.
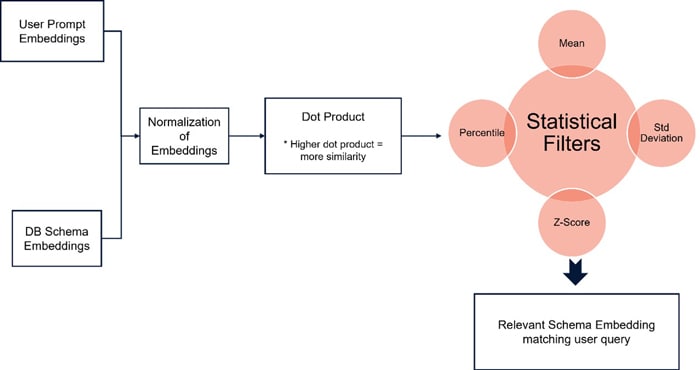
Dot Product with Statistical Filtering: Computes the dot product between the user embedding and each schema embedding. Embeddings are normalized prior to scoring. Statistical filters (mean, standard deviation, percentile, z-score) are applied to dynamically select a threshold. This approach is computationally lightweight and tunable, offering high control over the filtering logic.
Figure 3: Dot Product Flow
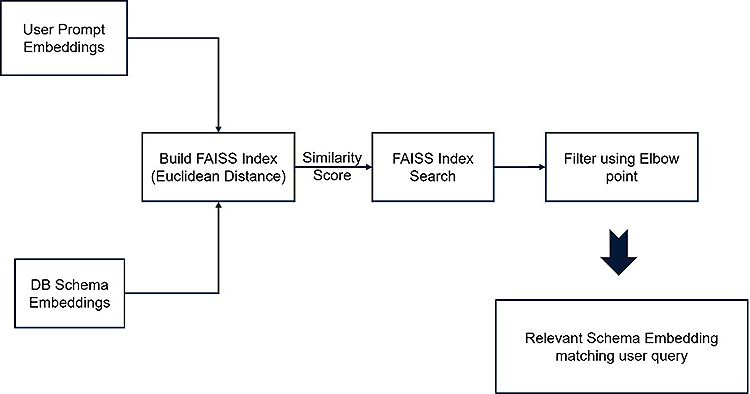
FAISS-Based Semantic Retrieval: Uses FAISS with a flat L2 index for fast approximate nearest neighbor search. The user embedding is matched against pre-indexed schema embeddings. An elbow-point detection algorithm (based on curvature) is applied to the similarity curve to determine an optimal cutoff.
Figure 4: FAISS Flow
4. Context Assembly and Query Generation
Once relevant schema elements are retrieved, any associated foreign key relationships are resolved using SQL queries on the schema metadata. This step ensures the prompt includes all necessary relational context. The relevant schema context is then combined with the original user query and sent to the LLM (Azure OpenAI) for SQL generation.
5. Validation and Execution
The generated SQL is validated syntactically and optionally tested for safe execution.
Evaluation Method
To evaluate the effectiveness of different schema retrieval strategies, we tested all three methods—Brute Force, Dot Product, and FAISS-based retrieval—on a common dataset using consistent prompts and metrics. All tests were run in a controlled local environment using a C# backend integrated with Azure OpenAI and schema retrieval components.
Dataset: Sakila Database
The Sakila database is a well-known open-source schema designed to simulate the operations of a DVD rental store. It includes 16 interrelated tables representing customers, payments, rentals, films, categories, inventory, staff, and locations. The schema contains over 120 columns and approximately 46,000 records. Its structure reflects real-world business relationships, making it ideal for evaluating schema-based query generation.
Prompt Strategy
We selected two representative natural language queries, each designed to test different levels of schema complexity. Each prompt was processed using all three retrieval methods, keeping the LLM configuration and generation logic constant.
Metrics Collected
For each method and query combination, we measured the following:
- Input Tokens: Number of tokens sent to the LLM.
- Completion Tokens: Number of tokens generated in the response.
- Total Token Usage: Sum of input and output tokens.
- Cost Estimate: Based on OpenAI’s token pricing.
- Latency: Time taken from submission to response.
Results and Analysis
To evaluate the effectiveness of each schema retrieval strategy, two representative prompts were tested across Brute Force, Dot Product, and FAISS methods. Metrics collected include input and output tokens, total cost (based on OpenAI pricing), and latency. All methods successfully generated valid SQL queries.
Pricing: $30 per 1M input tokens, $60 per 1M output tokens (OpenAI standard as of evaluation).
Prompt 1: What are the movies done by Penelope?
| Method | Input Tokens | Output Tokens | Latency | Total Cost (USD) |
|---|---|---|---|---|
| Brute Force | 4190 | 57 | 2102ms | 0.12912 |
| FAISS | 687 | 63 | 1024ms | 0.02439 |
| Dot Product | 1069 | 52 | 1592ms | 0.03519 |
Brute Force used all 120 schema embeddings and 22 relationships.
Dot Product filtered down to 21 embeddings and 9 relationships.
FAISS reduced this further to 10 embeddings and 6 relationships.
Insights:
FAISS reduced cost by ~82% compared to Brute Force.
Dot Product achieved ~73% cost savings with less implementation overhead than FAISS.
FAISS had the lowest latency.
Prompt 2: How many films are rented by all the customers which starred actor Penelope?
| Method | Input Tokens | Output Tokens | Latency | Total Cost (USD) |
|---|---|---|---|---|
| Brute Force | 4198 | 79 | 2739ms | 0.13064 |
| Dot Product | 1285 | 89 | 2576ms | 0.04389 |
| FAISS | 875 | 79 | 1946ms | 0.03099 |
Brute Force again used the full schema and all relationships.
Dot Product selected 22 embeddings and 14 relationships.
FAISS selected 10 embeddings and 11 relationships.
Insights:
FAISS again delivered the most compact and cost-effective solution.
Dot Product showed strong performance, with slightly higher cost and latency than FAISS.
Brute Force remained the most expensive and slowest.
All three methods created correct SQL query which were executable.
FAISS retrieval was the most cost-efficient, reducing total token cost by ~82% compared to brute force.
Dot Product offered substantial improvements with less complexity than FAISS, reducing cost by ~73%.
Brute Force is clearly the most expensive and least scalable option.
Observations
All methods produced correct and executable SQL queries.
FAISS retrieval consistently delivered the best performance, reducing token usage and cost by over ~80% while maintaining or improving latency.
Dot Product retrieval provided a strong middle ground, achieving similar quality with simpler implementation and no dependency on external indexing libraries.
Brute Force, while simple, is clearly inefficient and unscalable, especially for larger or more complex schemas.
Discussion
The results demonstrate that both FAISS and Dot Product retrieval strategies significantly outperform the brute-force approach in terms of token efficiency, cost, and latency. However, selecting between them depends on the system's design goals, operational scale, and deployment constraints.
When to Use Dot Product Retrieval
The Dot Product method, backed by statistical filtering, offers a lightweight and interpretable alternative. It avoids the need for external indexing libraries or persistent vector stores and can be implemented using standard numerical libraries. This makes it well-suited for:
- Small to medium-scale systems
- Resource-constrained environments
- Scenarios where simplicity, control, and transparency are priorities
- Use cases that don’t demand real-time, high-throughput performance
It’s especially advantageous when embeddings are limited in number (e.g., <10,000), and when you want deterministic control over filtering thresholds.
When to Use FAISS Retrieval
FAISS-based retrieval excels in performance at scale. It enables approximate nearest-neighbor search with low latency, making it ideal for:
- Large schemas or multi-database setups
- Applications that require low response times
- Use cases where embeddings are large, frequently queried, and reused
The use of an elbow-point algorithm helps avoid arbitrary top-K cutoffs and adapts to query-specific similarity distributions.
Trade-offs with Vector Databases
While solutions like Pinecone, Weaviate, or Milvus offer managed similarity search with advanced features (e.g., metadata filtering, distributed indexing), they also introduce:
- Operational overhead
- Dependency on external services
- Often higher latency and cost for smaller or less dynamic use cases
In contrast, this solution demonstrates that FAISS alone can deliver high efficiency without requiring full vector database infrastructure: making it a more controlled, self-contained, and cost-effective choice for structured schema retrieval.
Brute Force as a Baseline
Though brute force provides full coverage, it does so at a significant cost. It introduces scalability bottlenecks and should only be used for prototyping or as a fallback when retrieval logic fails.
Conclusion
- All three retrieval methods: Brute Force, Dot Product, and FAISS—were able to generate correct and executable SQL queries when used with an LLM.
- Brute Force consistently had the highest token usage, cost, and latency, making it unsuitable for scalable or production-grade systems.
- The Dot Product method:
- Reduced cost by ~73% over Brute Force
- Required minimal infrastructure
- Offered deterministic control through statistical filters
- The FAISS method:
- Reduced token cost by ~82%
- Achieved lowest latency
- Best suited for high-scale and real-time applications
- FAISS retrieval can be used without a full vector database, making it lighter and easier to integrate while still highly efficient.
- The choice between Dot Product and FAISS should be based on:
- Dataset size
- Performance needs
- Infrastructure complexity
- Intelligent schema retrieval strategies like these are essential for building cost-effective, scalable text-to-SQL systems and can be generalized to other LLM use cases involving structured context.
References






Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!