Artificial Intelligence




DeepSeek Architecture and The Aha Moment
This white paper examines the architectural innovations, engineering advancements, and practical implications of DeepSeek models for enterprise adoption. By implementing novel approaches to model architecture, training methodologies, and hardware utilization, DeepSeek offers enterprise organizations an opportunity to deploy state-of-the-art AI capabilities while significantly reducing computational overhead and associated costs.
For enterprise architects, CTOs, and data scientists, DeepSeek provides a compelling option for organizations seeking to deploy advanced AI capabilities within pragmatic infrastructure and budget constraints.
Insights
- DeepSeekMoE: A refined Mixture-of-Experts architecture offering superior parameter efficiencyCover 3-5 main bullet points in this box
- Multi-head Latent Attention (MLA): A breakthrough approach to reducing memory requirements
- Multi Token Prediction: enhancement of training efficiency and model performance by extending the traditional next-token prediction to predicting multiple future tokens at each position in the sequence
- DeepSeek R1: Reinforcement learning for advanced reasoning capabilities
- FP8 Training Framework: Low-precision computation with high-quality outputs
Introduction
The evolution of Large Language Models (LLMs) has been marked by significant technical challenges that once seemed insurmountable. DeepSeek has emerged as a pioneering force that has systematically addressed these barriers through ingenious architectural innovations and engineering breakthroughs rather than simply scaling computational resources.
DeepSeek's journey began with the fundamental recognition that the path to more capable AI systems required rethinking core architectural principles. The team identified that conventional approaches to scaling models faced diminishing returns and inherent inefficiencies in both training and inference. Rather than accepting these limitations, DeepSeek pursued novel solutions that would unlock new capabilities while simultaneously reducing computational demands.
A cornerstone of DeepSeek's innovation has been the DeepSeekMoE architecture, which revolutionized the Mixture-of-Experts paradigm. While previous MoE implementations struggled with knowledge hybridity and redundancy issues, DeepSeek pioneered fine-grained expert segmentation and shared expert isolation strategies. These innovations dramatically improved expert specialization, enabling models to acquire more precise knowledge and achieve previously unattainable performance levels. The architecture allowed DeepSeekMoE 16B to achieve comparable performance to dense models with 2.5 times more activated parameters¹, demonstrating that architectural innovation could outperform brute-force scaling.
DeepSeek further revolutionized attention mechanisms with Multi-head Latent Attention (MLA), which addresses the memory bottleneck during inference without compromising model quality. This innovation significantly reduced Key-Value cache requirements during generation while maintaining performance comparable to standard attention mechanisms.
On the training infrastructure front, DeepSeek developed the HAI-LLM framework featuring groundbreaking advances like the DualPipe algorithm for pipeline parallelism, which dramatically reduced communication overhead during cross-node expert parallelism. Their customized all-to-all communication kernels fully utilized hardware capabilities while conserving critical compute resources. DeepSeek also pioneered an FP8 mixed precision training framework that validated, for the first time, the feasibility of FP8 training on extremely large-scale models.
Remarkably, these technical advancements have yielded extraordinary cost efficiency as a natural byproduct rather than as the primary objective. DeepSeek-V3, with 671B total parameters, required only 2.788M H800 GPU hours for its complete training² - an unprecedented achievement in training efficiency. The model achieved state-of-the-art performance across diverse benchmarks, particularly excelling in reasoning, code, and mathematical tasks, while maintaining a prudent total training cost.
DeepSeek's approach demonstrates that the future of AI advancement lies not merely in increasing computational resources but in fundamental architectural innovations and engineering breakthroughs that enhance model capabilities while naturally improving cost efficiency. This philosophy of "doing more with less" continues to guide DeepSeek's research agenda as they push the boundaries of what's possible in artificial intelligence.
A Paradigm Shift in AI Economics
For enterprise decision-makers, DeepSeek's innovations represent not merely an incremental improvement, but a genuine paradigm shift in AI economics.
This transformation is driven by five key technical breakthroughs:
DeepSeekMoE architecture delivers comparable performance to models with 2.5× more activated parameters while requiring only 40% of computational resources. This translates directly to reduced hardware costs and energy consumption. (source: https://arxiv.org/pdf/2401.06066 , page 3, page 19)
Multi-head Latent Attention (MLA) dramatically reduces memory requirements during inference through low-rank compression of key-value pairs, enabling deployment on more modest hardware without performance loss.
Multi-Token Prediction enables models to generate approximately 1.8× more tokens per second, fundamentally improving the computation-to-output ratio for applications requiring high throughput. (source: https://arxiv.org/pdf/2412.19437 page 35, section 5.4.3)
DeepSeek R1's reinforcement learning approach brings advanced reasoning capabilities to more efficient architectures, eliminating the need for prohibitively expensive larger models.
The FP8 Training Framework maintains high-quality output while using low-precision computation, reducing training costs from potential millions to thousands of dollars. (source: https://arxiv.org/pdf/2412.19437 , sections 3.3-3.3.3)
Together, these innovations have reduced the training costs of cutting-edge models to approximately $5.6 million (source: https://arxiv.org/pdf/2412.19437 page 5, Table 1) fraction of the hundreds of millions typically required—democratizing access to advanced AI capabilities across enterprises of varying sizes and resources.
We would explore key innovations in the subsequent sections.
DeepSeekMoE: Reimagining Mixture-of-Experts Architecture
DeepSeekMoE represents a significant evolution of the traditional Mixture-of-Experts (MoE) architecture, designed to maximize computational efficiency while maintaining—or even enhancing—model performance.
Figure 1: Architecture
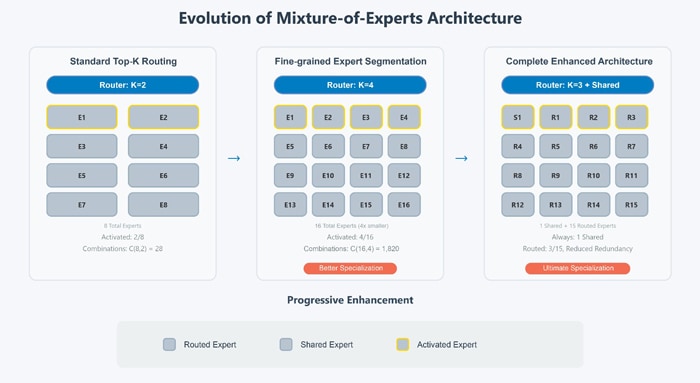
Conventional Approach (Left Panel)
- Uses a small number of large experts (N experts)
- Each input activates just a few experts (K=2)
- Business Problem: Experts try to learn too many different things, leading to inefficient use of parameters
Fine-grained Segmentation (Middle Panel)
- Split each expert into smaller pieces (2N experts)
- Activates more experts per input (K=4)
- Business Value: More granular specialization without increasing computation
DeepSeekMoE (Right Panel)
- Maintains granular experts but dedicates some as "shared experts"
- Shared experts handle common knowledge, while routed experts handle specialized knowledge
- Business Value: Further improves parameter efficiency by reducing redundancy across experts
According to the DeepSeekMoE paper, the architecture includes two principal strategies (b and c in the image above) working in tandem.
This combined approach addressed two key issues identified in conventional MoE models:
- Knowledge Hybridity: When tokens with diverse knowledge are assigned to a single expert.
- Knowledge Redundancy: When multiple experts duplicate common knowledge.
Google developed GShard as a distributed framework that enables efficient training and scaling of massive neural network models—containing hundreds of billions of parameters—across multiple hardware accelerators like TPUs or GPUs. Its significance lies in its ability to train models substantially larger than single-device capacity through the combined use of conditional computation and automatic sharding techniques.
GShard uses the conventional top-2 routing strategy, as shown in subfigure (a) of the illustration. In this approach, for each token, the router selects the top 2 experts (K=2) out of N available experts. This is a standard MoE (Mixture-of-Experts) implementation where each expert is structurally identical to a standard FFN (Feed-Forward Network), and tokens are assigned to a limited number of experts to maintain computational efficiency.
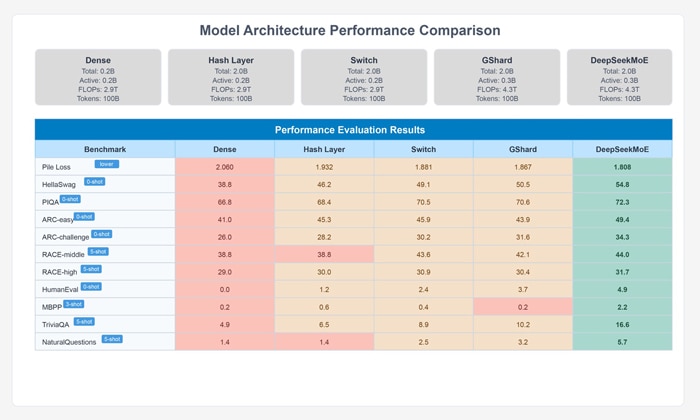
Through extensive evaluation shown in the table below, the DeepSeek research team demonstrated that this dual-strategy approach outperforms both GShard and dense models of comparable size, approaching the upper bound performance for MoE models while using fewer computational resources.
Figure 2: Benchmark Data
Fine-Grained Expert Segmentation
Breaking down experts into smaller, more specialized units by splitting the FFN intermediate hidden dimension. This allows diverse knowledge to be decomposed more finely across different experts
DeepSeekMoE dramatically increases expert granularity, fragmenting conventional experts into smaller, more specialized units. Where traditional MoE models might employ 16 large experts with top-2 routing, DeepSeekMoE segments these into a much larger number of smaller experts (e.g., 64 experts, each with 1/4 the parameters of a standard expert).
This approach offers two critical advantages:
Combinatorial Flexibility:
With 64 fine-grained experts selecting 8, the possible combinations increase from 120 to over 4.4 billion, enabling much more nuanced specialization. Looking at it from a combinatorial perspective, the fine-grained expert segmentation strategy is giving a tremendous boost to the flexibility of activated experts.
Let us take an example where N = 16 (total experts) and we need to select top 2 experts, in this traditional top 2 routing approach, one can get only ( = 120 possible combinations. When each expert is divided into 4 smaller ones, the fine-grained routing strategy can produce ( = 4,426,165,368 potential combinations!
The calculation is simply based on the mathematical combination formula only:
- In the conventional approach: (16 choose 2) = 120 combinations
- In the fine-grained approach: (64 choose 8) = 4,426,165,368 (approximately 4.4 billion) combinations
Combinatorial flexibility increases by a factor of approximately 36.9 million, from 120 possible combinations to 4,426,165,368 potential combinations!
Shared Expert Isolation
DeepSeekMoE introduces the concept of explicitly designated "shared experts" that process every token, alongside the selectively routed experts. These shared experts capture fundamental, cross-domain knowledge needed for most inputs, eliminating redundancy in the specialized experts.
Benefits include:
Reduced Parameter Redundancy: Common knowledge is consolidated in shared experts rather than duplicated across multiple specialized experts.
Enhanced Specialization: Routed experts can focus exclusively on domain-specific knowledge, increasing their effectiveness.
Figure 3: Performance Comparison

The figure shows a comparison between GShard and DeepSeekMoE with half the activated experts (trained from scratch) across six different benchmark metrics. The blue bars represent the GShard architecture (0 shared expert + 2 out of 16 routed experts), while the orange bars represent the DeepSeekMoE architecture with reduced compute (1 shared expert + 3 out of 63 routed experts). Here, DeepSeekMoE outperforms GShard across all six benchmarks despite using only half the activated expert parameters.
The metrics shown include:
- HellaSwag: Testing language understanding and reasoning
- PIQA: Testing physical commonsense reasoning
- ARC-easy: Testing elementary science knowledge
- ARC-challenge: Testing more complex science reasoning
- TriviaQA: Testing factual question answering
- NaturalQuestions: Testing real-world question answering
This result demonstrates DeepSeekMoE's strong expert specialization and efficient parameter utilization. Even with half the computational resources, it achieves better performance than GShard, highlighting how the architecture's design choices (fine-grained expert segmentation and shared expert isolation) lead to more effective knowledge acquisition and specialization.
Auxiliary-Loss-Free Approach:
The Problem with Conventional Load Balancing
In MoE architectures, input tokens are routed to different expert networks, creating two major issues:
- Unbalanced Expert Usage: Some experts receive too many tokens while others remain underutilized.
- Training Inefficiency: Computational resources become bottlenecked by overloaded experts.
- Performance Limitations: Uneven training across experts reduces overall model capabilities.
Conventional solutions add auxiliary loss terms that penalize imbalance, but this conventional approach:
- Creates conflicting gradients that work against the main training objective
- Requires complex tuning of additional hyperparameters
- Forces a difficult trade-off between balance and performance
- DeepSeek-V3 further refines the MoE architecture with an auxiliary-loss-free approach.
Auxiliary-Loss-Free Load Balancing Solution
The DeepSeek approach maintains balanced expert loads without introducing harmful additional training signals. Traditional auxiliary loss approaches create conflicting optimization goals that can degrade model performance. Consider a routing scenario where an expert specializes in processing financial information.
The following example shows how traditional methods create "harmful" training signals by introducing mathematical terms directly into the loss function that works against the primary goal of routing tokens to the most appropriate experts.
When a financial query appears:
With traditional auxiliary loss:
- The main training objective strongly encourages routing this financial query to the financial expert for best response quality
- Simultaneously, if the financial expert is already handling many queries, the auxiliary loss penalizes sending more tokens to it
- These contradictory signals create a dilemma: either compromise quality (by routing to a less suitable expert) or accept imbalance (by ignoring the auxiliary loss)
With Auxiliary-Loss-Free Balancing:
- The system observes the financial expert is handling too many queries
- Instead of adding a penalty during gradient computation, it simply adjusts the bias term for that expert
- Future financial queries might be routed to the second-best expert for financial topics until load balances out
- This happens without interfering with the learning process itself
How It Works
- Expert Bias Mechanism: The DeepSeek team applies adjustable bias values to expert routing scores before selection
- Automatic Adjustment: Biases are updated based on recent usage—reducing scores for busy experts and increasing them for idle ones
- No Gradient Interference: These adjustments happen outside the gradient computation, preserving training quality
Enterprise Implications of DeepSeekMoE:
For enterprise deployment, DeepSeekMoE and its architectural innovations offers several compelling advantages:
- Cost Efficiency: Achieves performance comparable to much larger dense models using 60-70% less computation, translating to proportional infrastructure cost savings.
- Inference Latency: Reduced computational requirements enable faster response times for end-user applications.
- Deployment Flexibility: The architecture allows for efficient distribution across heterogeneous compute resources, enabling optimal resource utilization in enterprise environments.
- Scaling Characteristics: By activating only, a fraction of parameters for each input, inference capacity scales more efficiently with increasing model size.
Now we would explore another important mechanism MLA which makes DeepSeek architecture interesting.
Multi-head Latent Attention (MLA): Memory-Efficient Attention Mechanism
One of the most significant bottlenecks in deploying large language models in production environments is the Key-Value (KV) cache memory requirement. During text generation, standard Transformer architecture must store the attention keys and values for all previously generated tokens, leading to memory usage that scales linearly with sequence length.
DeepSeek addresses this challenge through Multi-head Latent Attention (MLA), which fundamentally rethinks how attention states are stored and processed.
(please refer following diagram in the reference paper) Refer Figure 2 - Multi-head Latent Attention Architecture Diagram. (Page -7 in PDF version)
The diagram depicts how MLA works, including:
- The low-rank joint compression for attention keys and values
- The creation of compressed latent vectors
- The flow of information through up-projection matrices
- How RoPE (Rotary Positional Embedding) is applied
The figure specifically illustrates how MLA reduces Key-Value (KV) cache during inference, which is one of its key benefits. The diagram shows that only certain vectors (marked in blue boxes in the original diagram) need to be cached during generation, which significantly reduces memory requirements while maintaining performance comparable to standard Multi-Head Attention.
Unlike approaches like Multi-Query Attention (MQA) or Grouped-Query Attention (GQA) that reduce memory by sharing keys and values across attention heads (accepting performance degradation), MLA maintains the expressive power of full multi-head attention while achieving comparable memory savings through:
Low-rank Factorization: MLA applies a low-rank factorization to compress key-value information into a compact latent representation. This is explained in subsequent section.
Dynamic Decompression: During inference, this latent vector is dynamically decompressed to produce the full-dimension keys and values needed for attention computation.
Figure 4: Low Rank Factorization -Matrix Decomposition
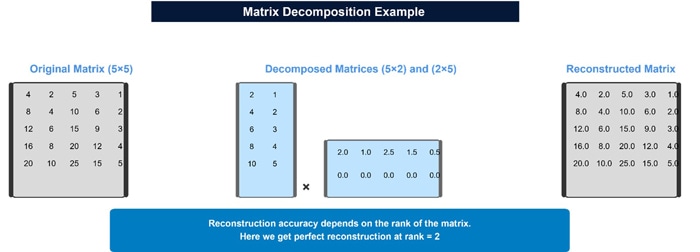
The low-rank factorization in MLA works by compressing the key and value matrices into a more compact latent representation.
Traditional Attention
In standard Multi-Head Attention (MHA), for each token, you compute full key (K) and value (V) vectors for each attention head. These vectors need to be stored in memory during generation, creating a substantial memory requirement known as the "KV cache."
MLA's Approach
MLA compresses this information through low-rank factorization, which works as follows:
Shared Latent Representation:
Instead of computing and storing separate full-dimensional keys and values for each attention head, MLA first projects the hidden input into a shared, lower-dimensional latent space:
cᵏᵛₜ = Wᴰᴷⱽhₜ
Where:
- hₜ is the input hidden state for token t
- Wᴰᴷⱽ is the down-projection matrix
- cᵏᵛₜ is the compressed latent vector with dimension dᶜ (much smaller than d×nₕ)
Factorized Reconstruction:
When needed, the full-dimensional keys and values can be reconstructed from this compressed representation:
kᶜₜ = Wᵁᴷcᵏᵛₜ
vᶜₜ = Wᵁⱽcᵏᵛₜ
Where:
- Wᵁᴷ and Wᵁⱽ are up-projection matrices
- kᶜₜ and vᶜₜ are the reconstructed content keys and values
Position Information:
Additionally, MLA uses a separate rotary positional embedding (RoPE) on a special key:
kᴿₜ = RoPE(Wᴷᴿhₜ)
In DeepSeek, RoPE (Rotary Positional Embedding) encodes token positions through rotational transformations applied to query and key vectors, enabling relative position awareness while maintaining generalization capabilities for extended sequences. The implementation strategically balances positional information benefits with computational efficiency, particularly within compressed attention architectures.
During inference, only the compressed latent vector cᵏᵛₜ and the positional key kᴿₜ need to be cached, not the full reconstructed keys and values.
Benefits
- Memory Efficiency: As stated in the DeepSeek-V3 technical report, cᵏᵛₜ ∈ ℝᵈᶜ is "much smaller than dₕnₕ," which means the KV cache is significantly reduced.
- Inference Speed: Smaller KV cache means faster context processing, especially for long contexts.
- Model Scaling: This efficiency allows larger models to run on the same hardware. This approach is particularly valuable for deployment scenarios where memory constraints are a concern, but model quality needs to be maintained.
Enhanced MLA in DeepSeek-V3
DeepSeek-V3 further refines the MLA approach with several key improvements:
- Dynamic Compression Ratios: Adaptively adjusts compression levels based on sequence length, using less compression for shorter sequences and deeper compression for very long contexts.
- Depth-aware Query Compression: Scales query dimensions based on layer depth, with earlier layers using higher dimensions for better expressiveness.
- Improved Position Embeddings: Enhanced handling of positional information enables stable 128K context window processing.
- Unified KV Storage: Combines compressed keys and values into a single representation, further reducing memory traffic during inference.
- Progressive Cache Pruning: Selectively prunes older KV entries at deeper layers for extremely long contexts.
Enterprise Benefits of MLA
For enterprise deployments, MLA offers several substantial benefits:
- Extended Context Window: Enables processing of documents up to 128K tokens without specialized hardware.
- Reduced Infrastructure Costs: Lower memory requirements translate directly to reduced GPU/TPU requirements and associated costs.
- Higher Throughput: Memory efficiency enables handling more concurrent requests with existing infrastructure.
- Deployment Flexibility: Makes high-capability models viable on a wider range of hardware configurations
Multi-Token Prediction (MTP): Enhancing LLM Performance and Efficiency
MTP extends the prediction scope to multiple future tokens at each position, rather than just predicting the next single token. Unlike some approaches that predict additional tokens in parallel, DeepSeek-V3 sequentially predicts additional tokens while maintaining the complete causal chain at each prediction depth.
Each MTP module consists of:
- A shared embedding layer
- A shared output head
- A Transformer block
- A projection matrix
Training Objective:
For each prediction depth, they compute a cross-entropy loss, and then average these losses across all depths, applying a weighting factor.
Figure 5: MTP (Multi-Token Prediction) Architecture
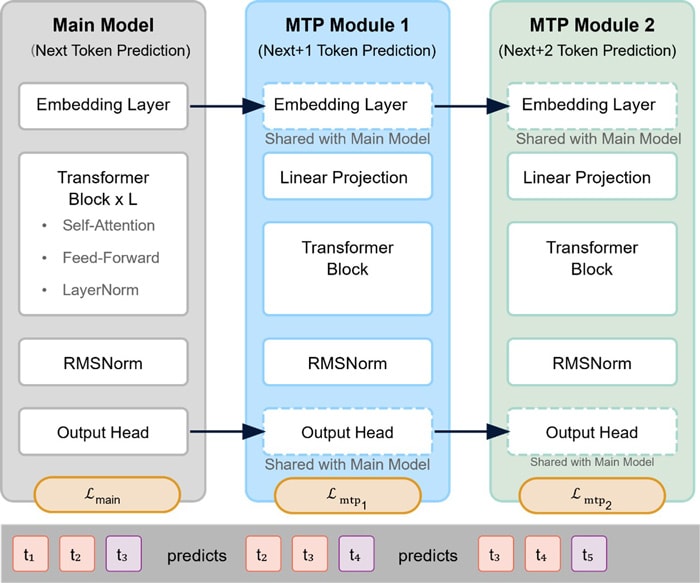
The figure shows:
- Main Model Structure: The standard model component that predicts the next token (t₃) based on previous tokens (t₁, t₂).
- MTP Module 1: The first MTP module that predicts token t₄ (the token after the next) using context including t₂ and t₃.
- MTP Module 2: The second MTP module that predicts token t₅ (two tokens ahead) using context including t₃ and t₄.
Key features illustrated in the diagram:
- Shared Components: The dashed boxes indicate components shared between the main model and MTP modules (embedding layer and output head).
- Module-Specific Components: Each MTP module has its own linear projection and transformer block.
- Sequential Prediction: The token sequence at the bottom shows how each module predicts progressively further into the future.
- Loss Functions: The separate loss functions for each prediction depth are shown.
Benefits:
MTP offers substantial benefits in both training and inference scenarios:
- Enhanced Model Performance: Empirical evaluations demonstrate that MTP consistently improves model performance across diverse benchmarks, including language understanding, reasoning, and knowledge-intensive tasks.
- Speculative Decoding: During inference, MTP modules can be repurposed for speculative decoding, predicting future tokens in advance and significantly improving generation speed.
- Inference Acceleration: Models trained with MTP have demonstrated acceptance rates of 85-90% for the second token predictions, resulting in up to 1.8x improvement in tokens per second (TPS) during text generation.
- Flexible Deployment: The MTP approach allows for flexible deployment strategies - the modules can be discarded for standard inference or leveraged for accelerated generation when speed is critical
DeepSeek R1: Advancing Reasoning Through Reinforcement Learning
The Reasoning Challenge in LLMs
While large language models demonstrate impressive language capabilities, complex reasoning remains a challenging frontier. DeepSeek R1 represents a novel approach to enhance reasoning capabilities through reinforcement learning without requiring extensive human supervision.
Pure Reinforcement Learning Approach
DeepSeek R1-Zero represents a groundbreaking achievement in AI research—a model trained via largescale reinforcement learning without supervised fine-tuning as a preliminary step.
Key innovations in this approach include:
Rule-based Rewards: Instead of using human feedback or neural reward models, DeepSeek R1 employs objective, rule-based rewards:
Accuracy rewards:
Based on verifiable outputs in domains like mathematics and coding.
Format rewards:
Encouraging structured thinking and answer presentation. DeepSeek R1 employs a specific template structure that guides the model's output format. The format rewards encourage the model to:
- Place its thinking process between '
' and ' ' tags. This creates a clear separation between the model's reasoning process and its final answer. - Present the final answer within a specified format (e.g., within a box or designated tags) to enable reliable rule-based verification of correctness.
- Follow a structured template that guides the model to "first think about the reasoning process in the mind and then provide the user with the answer" with reasoning enclosed in
tags and answers in tags.
For example, a typical format would look like

This format structure serves multiple purposes:
- It encourages the model to explicitly show its reasoning steps
- It helps separate the internal reasoning from the final response
- It makes it easier to automatically evaluate correctness
- It creates a consistent structure that can be reliably rewarded during training
Self-Evolution:
Through pure reinforcement learning, the model naturally develops sophisticated reasoning behaviors:
- Extended "thinking time" for complex problems
- Reflective reasoning strategies
- Exploration of alternative approaches
- Self-verification of proposed solutions
GRPO and The "Aha Moment" Phenomenon
One of the most fascinating developments in the DeepSeek R1 training process was the emergence of an "Aha Moment" phenomenon, where the model spontaneously develops reflective reasoning capabilities. This is achieved using GRPO (Group Relative Policy Optimization) where multiple solutions are created. Imagine you're training a model to write effective business emails. For a prompt about requesting a meeting with a client, the model generates multiple different responses:
- One response might be formal and direct, clearly stating the purpose upfront
- Another might begin with rapport-building before making the request
- A third might emphasize the mutual benefits of the meeting
- Others might vary in tone, structure, or persuasion techniques
All these attempts are evaluated as a group, like how a coach would compare different batting techniques side by side to determine which is most effective.
The genius of GRPO lies in how it determines which responses to reinforce. Rather than requiring a separate model to judge each response (like traditional RL approaches), GRPO uses the relative performance within the group itself. Responses that perform better than the group average are reinforced, while those performing below average are discouraged.
The key innovation in GRPO is how it uses these rewards.
For each question, the algorithm:
- Samples a group of outputs {o₁, o₂, ..., oG} from the current policy
- Computes rewards {r₁, r₂, ..., rG} for each output
- Computes an advantage function Aᵢ for each output by normalizing its reward against the group:
Aᵢ = (rᵢ - mean({r₁, r₂, ..., rG})) / std ({r₁, r₂, ..., rG})
This advantage function serves as the signal for policy optimization. It encourages the model to generate outputs that are better than the group average and discourages outputs that are worse.
Practical Example
Will walk through a concrete example of how this works for a math problem:
- The model is asked: "What is the derivative of x²?"
- The model generates 4 different responses:
- Response 1: "The derivative of x² is 2x."
- Response 2: "The derivative of x² is 2x + C."
- Response 3: "The derivative is 2x because d/dx(x²) = 2x."
- Response 4: "The answer is x."
- The rule-based reward function evaluates each:
- Response 1: r₁ = 1.0 (correct)
- Response 2: r₂ = 0.7 (technically correct but unnecessarily adds a constant)
- Response 3: r₃ = 1.0 (correct with explanation)
- Response 4: r₄ = 0.0 (incorrect)
- GRPO computes:
- mean({1.0, 0.7, 1.0, 0.0}) = 0.675
- std({1.0, 0.7, 1.0, 0.0}) = 0.435
- A₁ = (1.0 - 0.675) / 0.435 = 0.747
- A₂ = (0.7 - 0.675) / 0.435 = 0.057
- A₃ = (1.0 - 0.675) / 0.435 = 0.747
- A₄ = (0.0 - 0.675) / 0.435 = -1.552
The policy is then updated to:
- Moderately increase probability of responses like 1 and 3
- Slight increase probability of responses like 2
- Strongly decrease probability of responses like 4
Key Benefits of GRPO's Reward Approach
- Efficiency: No need for a separate critic model that would double the parameter count.
- Robustness: Using relative comparisons within a group makes the algorithm less sensitive to the absolute scale of rewards.
- Adaptability: Works well with both rule-based and model-based rewards, making it versatile across different domains.
This internal comparison eliminates the need for a separate critic model of equivalent size, substantially reducing computational requirements while maintaining effective learning signals.
This approach enables DeepSeek-R1 to efficiently develop sophisticated reasoning capabilities without the computational overhead typically associated with large-scale reinforcement learning.
This phenomenon demonstrates:
- Metacognitive awareness (the model recognizing its own mistakes)
- Spontaneous development of human-like problem-solving strategies
- Emergent intelligence beyond what was explicitly programmed
Enterprise Applications of DeepSeek R1
For enterprise applications, DeepSeek R1's enhanced reasoning capabilities enable several advanced use cases:
- Complex Problem Solving: Superior performance on mathematical, logical, and programming challenges that require step-by-step reasoning.
- Transparent Decision Making: The explicit thinking process allows audit and verification of the model's reasoning.
- Knowledge Work Automation: More reliable handling of tasks requiring multi-step reasoning like financial analysis, legal document review, or technical troubleshooting.
- Training Efficiency: The approach demonstrates that specialized capabilities can be developed without extensive human annotation efforts.
DeepSeek Implementation Strategies and Ethical Considerations
Enterprise Implementation Approaches
Organizations considering DeepSeek implementation should evaluate several key factors:
Hardware and Deployment:
While DeepSeek uses less computation than comparable models, optimal performance requires modern GPUs with FP8 support. The architecture efficiently distributes across multiple GPU devices while minimizing communication overhead.
Integration Options:
Enterprise AI teams can integrate DeepSeek through direct API integration (simplest approach), local deployment (for data-sensitive applications), or a hybrid approach utilizing smaller models locally with larger variants accessed via API for complex tasks.
Use Case Prioritization:
Organizations should focus initial implementation on use cases where DeepSeek's strengths provide maximum business value:
- Complex reasoning tasks (financial analysis, legal review)
- Long-context applications (document analysis, research synthesis)
- High-throughput scenarios requiring efficient resource utilization
ROI Factors:
The business case should consider infrastructure costs (70-80% lower than comparable models), improved response time, capability thresholds enabling automation of complex knowledge work, and reduced operational overhead.
Ethical Framework for Responsible Deployment
Implementing DeepSeek in enterprise environments requires addressing several ethical dimensions:
Data Governance and Privacy:
Establish clear policies regarding how user inputs are processed, stored, and potentially used for model improvement. Content generated by DeepSeek should be clearly identified as AI-generated, particularly in decision-making processes.
Transparency and Fairness:
DeepSeek R1's explicit reasoning processes provide greater visibility into decision-making compared to black-box alternatives. However, organizations should implement continuous monitoring for emergent biases, particularly in sensitive applications.
Organizational Impact:
As DeepSeek automates increasingly complex reasoning tasks, enterprises should develop strategies for workforce transition and upskilling. Though DeepSeek reduces computational requirements, organizations should still evaluate the environmental impact of large-scale deployments.
Governance Structure:
Implement a structured approach including ethical review processes before deployment, monitoring mechanisms to track performance, clear feedback channels, and established remediation protocols.
For enterprise architects, CTOs, and data scientists, addressing implementation and ethical considerations together ensures that DeepSeek deployment maximizes business value while minimizing potential risks and unintended consequences.
Conclusion and Future Outlook
DeepSeek represents a significant advancement in the field of large language models, achieving remarkable performance with unprecedented efficiency. By rethinking fundamental aspects of model architecture, training methodology, and hardware utilization, DeepSeek establishes new benchmarks for what is possible in cost-effective AI development.
For enterprise architects, CTOs, and data scientists, DeepSeek offers a compelling alternative to traditional approaches, enabling deployment of state-of-the-art AI capabilities with reduced computational requirements and associated costs.
Key takeaways for enterprise decision-makers include:
- Architectural Innovation: DeepSeekMoE and MLA provide efficiency advantages that translate directly to lower deployment costs.
- Reasoning Capabilities: DeepSeek R1 demonstrates enhanced performance on complex tasks requiring multi-step reasoning, enabling automation of more sophisticated knowledge work.
- Implementation Flexibility: The models' reduced computational requirements provide more deployment options, from on-premises to cloud-based approaches.
- Future Development: The engineering innovations in DeepSeek suggest continued improvements in efficiency and capability are likely in future iterations.
As AI continues to transform enterprise operations, DeepSeek's approach to efficiency without compromise represents an important milestone in making advanced AI capabilities more accessible and cost-effective for organizations across industries.
References
- "DeepSeek-R1: Incentivizing Reasoning Capability" - DeepSeek-AI, JAN-2025,
- "AUXILIARY-LOSS-FREE LOAD BALANCING" - Lean Wang, Huazuo Gao, Chenggang Zhao, Xu Sun, Damai Dai, AUG-2024,
- "DeepSeek-V3 Technical", DeepSeek-AI, FEB-2025,
- "DeepSeekMoE: Towards Ultimate Expert" - DeepSeek-AI, JAN-2024
- https://huggingface.co/learn/llm-course/en/chapter12/3?fw=pt
- All Figures are self-created to illustrate concepts.






Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!