Data




Azure Synapse Pipelines Efficient Design Learnings
This whitepaper explores the use case of designing pipeline-based solutions, the challenges faced in pipeline design and provides best practices and strategies for creating efficient pipeline designs. These practices aim to enhance overall system performance while minimizing the cost of Synapse Analytics Services.
Insights
- Cloud adoption at scale involves migrating applications and large data to Public or Private Cloud. Data ingestion, transformation, and processing require careful planning and execution for efficiency and optimal resource use.
- Azure Synapse Pipelines offer a cloud-based ETL and data integration solution, enabling the creation of data-driven workflows to orchestrate large-scale data movement and transformation, while providing valuable insights into the data pipelines.
- This paper serves as a valuable resource for technical architects, cloud project leads and data engineers involved in designing efficient pipelines using Azure Synapse Analytics.
Introduction
Azure Synapse Analytics, a Microsoft platform, combines enterprise data warehousing and data integration into a unified managed service. Synapse workspace can include multiple pipelines primarily used to develop data-driven solutions for orchestrating large-scale data movement and transformation. Pipelines handling large data volumes and processing complex data can incur significant costs per run. Poorly designed pipelines can lead to degraded system performance and exceed budget forecasts.
Context
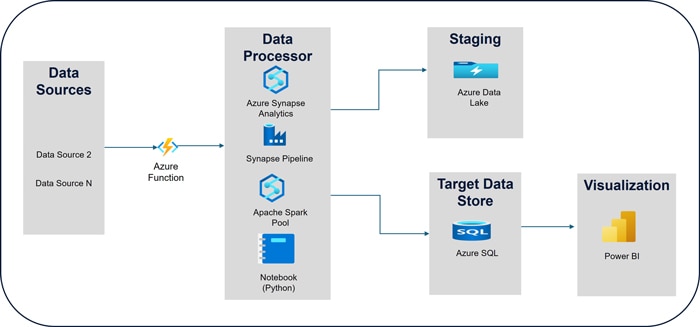
Consider an example of constructing an end-to-end pipeline-based solution to showcase the capabilities of Pipelines in Synapse Analytics Service. The high-level solution involves retrieving data from various sources, storing it in a data lake, processing it using Apache Spark Pools, and then storing the transformed data in a relational data store. In this scenario, Pipelines are triggered by events or on a defined schedule, with event-based pipelines enabling near real-time data processing. The high-level steps are as follows:
- When a specific event occurs, the source system posts metadata to the event grid.
- The event grid component triggers the execution of a subscribed Azure Function, passing the metadata to it.
- The Azure Function initiates the Synapse Pipeline and passes the metadata to it.
- The Pipeline extracts the metadata, connects to the specific data source, and retrieves data based on the provided metadata (e.g., order number).
- The Pipeline copies the input data to a data lake for audit purposes.
- The Notebook activity in the pipeline leverages Apache Spark Pool to apply rule-based algorithms for processing the input data and storing the output in the data lake.
- The Pipeline retrieves the processed data from the data lake, applies transformations, and loads the final data into the target data store.
- Finally, near real-time data is visualized using dashboards to gain various intelligent insights.
The following is a high-level solution design that illustrates the various components involved.
Challenges
Scaling cloud adoption involves migrating existing applications, deploying new ones, and transferring enormous amounts of data from on-premises to public or private clouds. Data ingestion, transformation, and processing can be complex tasks that require meticulous planning and execution to ensure a smooth process and optimal use of cloud resources.
Designing efficient pipelines can present several challenges, potentially increasing pipeline runtime, reducing system performance, and raising the cost of Synapse Analytics services. Key challenges observed, which may vary by project, include:
Lack of Multi-Skilled Talent: A diverse tech stack requires multi-skilled talent. Building complex data platforms requires experienced professionals with multiple skill sets in areas like Synapse pipelines, SQL Pools, Apache Spark, security etc. Without these skills, project teams may face challenges in designing efficient pipelines, resulting in suboptimal system performance.
Infrastructure Complexity: Cloud applications often involve multiple systems and applications that need strong interoperability for data exchange. The above use case required data flow between different distributed systems and application components. Designing efficient pipelines is difficult without a thorough understanding of the system and related interfaces.
Missing Capacity Planning: Failing to plan capacity for Synapse Analytics services and related components like pipelines, SQL pools, and data orchestration activities can lead to resource underutilization.
Improper Sizing of Apache Spark Pools: Apache Spark pools are used for big data processing tasks and are billed per vCore-hour, rounded to the nearest minute. If cluster sizing is not carefully selected, it will either impact pipeline performance or cause cost overruns, increasing the overall cost of Synapse services.
Using an outdated version of the Apache Spark library: This can result in performance bottlenecks and security vulnerabilities. This can cause pipelines to run longer, increasing overall operational costs. Additionally, not updating Apache Spark versions on time can lead to higher extended support costs.
Improper Pipeline Executions: Scheduling multiple pipelines to run in parallel increases the load on the system and degrades overall data platform system performance.
Inefficient Use of Pipeline Activities: If not evaluated properly, pipeline activities might take longer to complete for specific scenarios. Adjusting the order of activities can reduce pipeline execution duration and result in cost savings.
Default Timeouts: Most pipeline activities have default timeouts in hours or days. Not changing the default timeout value for each activity can allow activities to run longer in case of failures.
Missing Exception Handling: This is one of the key points that is often missed in ETL-based solutions. Inadequate exception handling can increase debugging and troubleshooting times for pipelines.
Lack of Source Code Management Tool: Not using a source code management tool for Synapse pipelines can be a significant challenge. It complicates the promotion of changes to higher environments and increases the likelihood of missing configuration changes, which can result in broken functionality.
Solutions to key challenges faced
The table below highlights the main challenges, solutions, and key benefits of designing efficient Synapse pipelines.
| Key Challenges | How to solve it? | Benefits |
|---|---|---|
| Unavailability of multi-skilled talents having experience in diverse tech stack | Invest in training programs to upskill employees. Implement cross-training programs where employees learn skills from different teams |
|
| Infrastructure Complexity | The Dev team should have a thorough understanding of system architecture, dependent applications, and interfaces along with data flows |
|
| Missing Capacity Planning | Perform initial capacity planning based on data volume and key parameters, refining as the project progresses |
|
| Not utilizing the latest version of the Apache Spark Library | Ensure to use the latest version of Apache Spark Library or upgrade the same to the latest version. These version checks must happen regularly |
|
| Inefficient Use of Pipeline Activities | Organize technical sessions on best practices and strategies for pipeline design, configuration, and security covering key scenarios. Explore and evaluate various scenarios for running pipelines and compare their execution times . The following scenarios are detailed in the "Best Practices and Strategies" section:
|
|
| Default Timeouts | Adjust default timeout values based on actual usage and patterns |
|
| Missing Exception Handling | Train the team on proper exception handling techniques and demonstrate various design methods. |
|
| Absence of Source Code Management Tool | Since pipeline code is stored in JSON format, it is crucial to use a source code management tool from the beginning of the project. Avoid making manual changes to the source code, as this can disrupt the entire Synapse workspace. Always make changes in a feature branch using Synapse Studio. |
|
Best Practices and Strategies
This paper shares insights from various data platform projects to help leverage best practices and strategies in future projects for optimal use of Azure Synapse Pipelines. While these insights are specific to data ingestion, transformation, and processing using Azure Synapse Analytics Service, they can also be applied to similar services on other cloud providers.
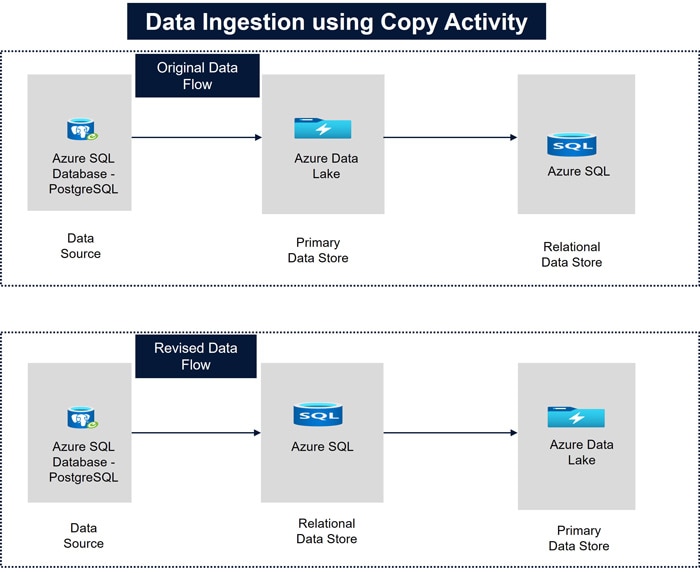
- Proper Use of Copy Activity: In one project, the data source was PostgreSQL, with data lake used as temporary storage and the final processed data stored in Azure SQL. Initially, the source data was copied from Azure PostgreSQL to data lake and then to Azure SQL. After analyzing the pipeline runtime, the design was updated to copy data from PostgreSQL to Azure SQL first, and then to data lake. This change reduced the pipeline execution time from 20 minutes to 16 minutes.
- Syncing Target Data with Source Data: Regular syncing is generally unnecessary in the development environment. Disabling triggers for hourly and daily pipelines saved approximately 15% of the monthly Synapse Analytics service cost in the development environment.
- Reducing Pipeline Execution Frequency: By analyzing synced data and highlighting cost benefits, the business agreed to reduce the frequency of specific pipeline executions from every hour to every two hours in higher environments (Test, Prod), saving approximately 5% of the monthly Synapse service cost.
- Avoiding Parallel Pipeline Execution: To reduce pipeline runtime, avoid running scheduled pipelines in parallel whenever possible. In our project, scheduling three pipelines to run simultaneously resulted in an approximately 20% increase in completion time, as the same integration runtime was shared across the pipelines. While compute capacity could be increased to mitigate this, it would unnecessarily raise overall costs. Therefore, it is advisable to schedule the pipelines at various times whenever feasible.
- Using Synapse Studio Monitoring: Synapse Studio provides out-of-the-box monitoring for data pipelines, offering insights such as execution time for each activity and the overall pipeline. Analyze long-running activities and optimize them.
- Disable VNET on Dev Environment: Pipeline activities run on the integration runtime. Configuring an integration runtime within a managed virtual network guarantees that the data integration process remains isolated and secure, utilizing private endpoints to connect safely to supported data stores, though this increases overall costs. To save significantly on costs in the development environment, avoid using VNET with private endpoints. However, this configuration should be enabled in higher environments.
- Estimating Data Volume and Capacity Planning: Estimate the volume of data ingestion, processing, and storage to appropriately plan and allocate resources. This will also assist in forecasting resource costs. While predicting the initial cost of Synapse Analytics services can be difficult due to most costs being consumption- or runtime-based, it is still possible to estimate these expenses through capacity planning. Consider the following pipeline-related factors for estimation:
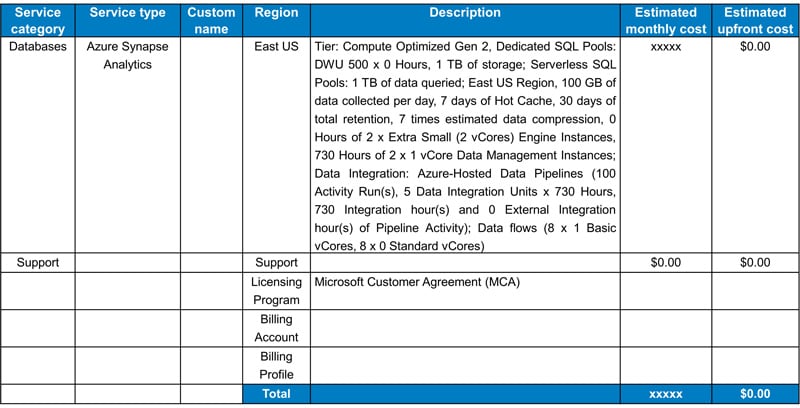
The snapshot below provides the cost for Synapse Analytics for reference. The description column outlines the details used to determine the cost based on the resource capacity planning.
- Apache Spark Pool Configuration
- Estimated Volume of Data Ingestion
- Number of Data Pipelines
- Managed Virtual Network (VNET)
- Type of Integration Runtime Selected (e.g., Azure Hosted Integration Runtime or Self Hosted Integration Runtime)
- Setting Appropriate Activity Timeouts: Adjust activity timeouts based on expected execution times. For example, if the default timeout is 10 minutes but the activity can be completed in 1 minute under adverse conditions, set the timeout to 1 or 2 minutes to save execution time in case of failures.
- Implementing Proper Exception Handling: Ensure proper exception handling in pipelines and notebooks to enable efficient debugging and troubleshooting. This includes the following:
- Use the "Fail" activity in the pipeline to indicate a failure.
- Implement proper error handling in child activities, ensuring they return accurate success or failure messages so the parent activity can determine the next appropriate action.
- If any activity in the pipeline fails, establish a robust rollback strategy to maintain data consistency.
- Leverage "UponFailure", "UponSkip", “UponCompletion” options in the notebook activity for error handling.
- Configure retry policies for pipeline activities, including notebook activities, to address transient issues.
Conclusion
Synapse Pipelines provide benefits like built-in activities for data migration, ingestion, transformation, and processing, along with scalability and flexibility. However, designing these pipelines poses challenges that can lead to poor system performance and increased cloud resource costs.
Successful pipeline design requires careful planning, experienced talent, proper capacity planning, and accurate data ingestion volume estimation. These best practices, developed through real-world experience, help maintain reliable, secure, and efficient pipelines, enhancing overall system performance.
References






Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!