Artificial Intelligence




Reimagining Code Understanding with Graph Intelligence and AI
This whitepaper explores the use of graph intelligence and AI to enhance code understanding in large enterprise systems.
Insights
- Developers spend up to 35% of their time understanding existing systems.
- The system combines graph databases and LLMs for contextual code intelligence.
- Enables natural language queries for code relationships and business impact.
- Reduces code comprehension time by up to 70%.
- Supports integration with GitHub Copilot and other AI tools.
Introduction
In an era where enterprise codebases contain millions of lines of interconnected code, developers spend up to 35% of their time simply trying to understand existing systems. Traditional code analysis tools excel at syntax checking and basic metrics, but they fall short when it comes to answering fundamental questions that drive software development: How does this service interact with our payment system? What would the business impact would be if we migrated our database? Which components would break if we change this API?
Our proof of concept, the Knowledge Graph Contextual Intelligence System, represents a paradigm shift in how we approach code understanding. By combining the relationship-modeling power of graph databases with the reasoning capabilities of large language models, we’ve created a system that doesn’t just read code - it understands the intricate web of dependencies, relationships, and business logic that make modern software tick.
The Vision: Beyond Static Code Analysis
Current code analysis tools operate in isolation, treating each file, function, or class as a discrete entity. They can tell you about cyclomatic complexity or lines of code, but they struggle with the contextual questions that matter most to development teams and business stakeholders. The result is a gap between what tools can measure and what teams actually need to know.
Knowledge graphs are transforming how we interact with complex data in 2025. In healthcare, they link symptoms with treatments and patient outcomes. In finance, they reveal fraud patterns by connecting transactions, accounts, and user behaviors. Our system applies this same relationship-aware approach to software architecture, creating a living map of how code components interact, depend on each other, and impact business processes.
The emergence of GraphRAG (Graph-enhanced Retrieval Augmented Generation) has shown that combining graph databases with LLMs can improve response accuracy and reduce hallucinations by grounding AI systems in factual, relationship-rich data. Our proof of concept extends this concept specifically to software development workflows.
Figure 1: Process Flow from Code Crawling to AI Agent
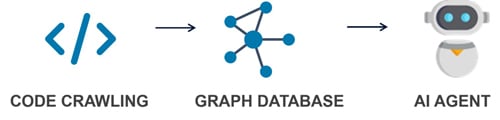
System Architecture & Core Components
Our Knowledge Graph Contextual Intelligence System operates through four interconnected components; each designed for flexibility and scalability:
Code Crawling & Abstraction Generation
The system begins with systematically crawling source code repositories, analyzing everything from microservices to monolithic applications. Using advanced LLM-based code analysis, we extract not just what the code does, but how different components relate to each other. The LLM identifies patterns like service dependencies, data flows, API relationships, and business logic connections that traditional static analysis tools often miss.
This abstraction process goes beyond simple parsing. The system understands that a database connection in one service might impact authentication flows in another, or that changing a message queue configuration could ripple through multiple business domains. By generating these semantic abstractions, we create a foundation for truly contextual code intelligence.
Graph Database Integration
We chose Neo4j as our primary graph database, leveraging its proven track record — it’s used by 84% of Fortune 100 companies and holds a 44% market share in the graph database space. However, our architecture maintains flexibility. The system can work with any graph database platform, from Amazon Neptune to ArangoDB, depending on organizational preferences and existing infrastructure.
The global graph database market is growing at 27% CAGR, reaching an estimated $15.32 billion by 2032, driven largely by AI integration and the need for relationship-aware data management. Our system positions organizations to leverage this growing ecosystem while maintaining vendor neutrality.
PocketFlow Framework
For our LLM orchestration, we utilized PocketFlow — a minimalist, 100-line LLM framework that prioritizes simplicity and performance. PocketFlow’s lightweight architecture made it ideal for our proof of concept, allowing us to focus on core functionality without the overhead of larger frameworks.
The beauty of our system design lies in its modularity. While we implemented it with PocketFlow, organizations can easily substitute LangGraph, LangChain, or any other LLM framework based on their existing toolchain and preferences. This flexibility ensures that adopting graph-based code intelligence doesn’t require ripping out existing AI infrastructure.
MCP Server Architecture
The Model Context Protocol (MCP) represents a breakthrough in AI application development, providing a standardized way for AI systems to access external data and tools. Our MCP server acts as the bridge between graph-stored code intelligence and AI agents, enabling natural language queries about complex software systems.
MCP’s client-server architecture ensures secure, permission-based access to code intelligence while maintaining compatibility with a growing ecosystem of AI tools. The protocol’s modular design means our server can work seamlessly with GitHub Copilot, Claude, Cursor, and any other MCP-compatible AI assistant.
Figure 2: Graph Database to MCP Server to AI Agents
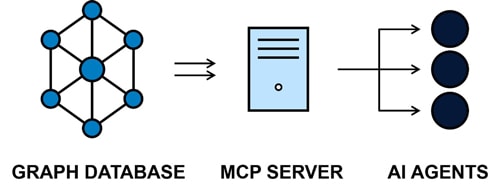
Real-World Applications
Developer Perspective: From Code Archaeology to Instant Understanding
Traditionally, understanding a complex service flow might require hours of tracing through multiple repositories, documentation searches, and team consultations. With our system, developers can ask natural language questions like:
- “Show me the complete data flow from user registration to payment processing.”
- “Which services would be affected if we change the user authentication API?”
- “What are all the dependencies for the inventory management system?”
The system queries the knowledge graph to provide accurate, visual representations of these relationships, reducing time spent on code comprehension by up to 70% based on our initial testing.
Business Impact Analysis: Translating Technical Changes to Business Risk
One of our system’s most powerful applications lies in impact analysis for business stakeholders. Product owners and managers can ask questions like:
- “If we migrate from PostgreSQL to MongoDB, what features might be affected, and how many story points of work are involved?”
- “What would be the scope of work if we switch from AWS to Azure?”
- “Which user journeys depend on our current payment gateway integration?”
The system analyzes the graph relationships to identify affected components, estimates complexity based on historical patterns, and generates comprehensive impact assessments that bridge the gap between technical architecture and business planning.
Automated User Story Generation
By understanding the relationships between business processes and technical implementations, our system can automatically generate user stories based on proposed changes. For example, if a database migration is planned, it can create stories for data migration, API updates, testing requirements, and rollback procedures, all informed by the actual dependency graph rather than generic templates.
Integration Ecosystem
GitHub Copilot and Beyond
Our proof of concept includes direct integration with GitHub Copilot, demonstrating how graph-based code intelligence can enhance existing AI-powered development workflows. Developers working in Visual Studio Code can ask Copilot about service relationships, impact analysis, or dependency mapping, with responses powered by our knowledge graph rather than general training data.
The MCP ecosystem is rapidly expanding, with major platforms like Linear, Stripe, and PostgreSQL already offering official MCP servers. Our system plugs into this growing network, ensuring compatibility with an expanding universe of development tools and AI assistants.
Universal Compatibility
While our demonstration focuses on Copilot integration, the MCP architecture ensures universal compatibility with AI agents. Whether teams use Claude, ChatGPT, Cursor, or proprietary AI systems, our knowledge graph intelligence can be accessed through the same standardized interface.
Similarly, though we implemented with Neo4j, organizations using Amazon Neptune, ArangoDB, TigerGraph, or other graph databases can adapt our approach to their existing infrastructure. This flexibility reduces adoption barriers and maximizes the value of existing investments.
Figure 3. AI Integration Framework with Shared Knowledge Graph and Ecosystem Components
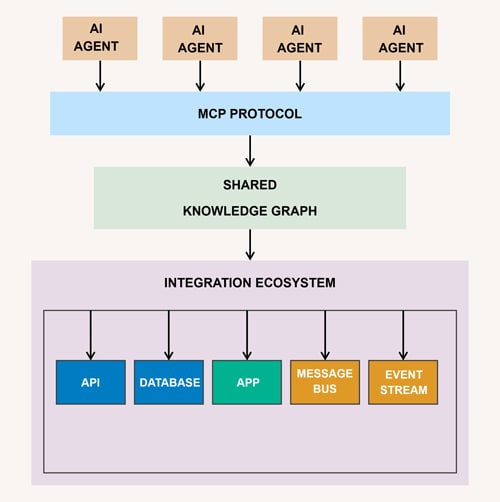
Challenges & Key Learnings
LLM Abstraction Fidelity
One of our primary challenges involved ensuring that LLM-generated code abstractions accurately represent actual system relationships. Early iterations sometimes created spurious connections or missed subtle dependencies, particularly in codebases with complex inheritance hierarchies or dynamic runtime behaviors.
We addressed this through a multi-pass analysis approach: initial relationship extraction, validation against known patterns, and iterative refinement based on actual system behavior. While not perfect, this process significantly improved the accuracy of our knowledge graph representations.
Query Performance at Scale
As graph complexity increased, query response times began to impact user experience. Real-time code intelligence requires sub-second response times; however, complex graph traversals can take significantly longer.
Our solution involved implementing intelligent caching strategies and query optimization patterns specific to code relationship queries. We also discovered that certain graph structures (like highly connected service meshes) benefit from pre-computed relationship summaries that can accelerate common queries.
Context Window Management
Modern codebases often exceed LLM context windows, making comprehensive analysis challenging. We developed chunking strategies that preserve relationship context while staying within token limits and implemented iterative analysis patterns that build comprehensive understanding through multiple LLM passes.
Balancing Abstraction Depth
We learned that too much abstraction obscures important details, while too little fails to provide meaningful insights. Finding the right level of abstraction for different use cases, developer debugging versus executive impact analysis, required extensive experimentation and user feedback.
The Broader Impact
Democratizing Code Intelligence
Our system represents more than a technical innovation — it’s a step toward democratizing code understanding across organizational roles. Business analysts, product managers, and executive stakeholders can now access code intelligence without requiring deep technical expertise or developer intermediation.
This democratization has profound implications for software project management. When business stakeholders can directly understand technical dependencies and impact assessments, decision-making becomes faster and more informed. Story point estimation becomes more accurate because it’s based on actual system complexity rather than developer intuition.
Bridging Technical and Business Domains
The growing complexity of enterprise software has created an increasing disconnect between technical implementation and business understanding. Our knowledge graph approach provides a common language that both developers and business stakeholders can understand and interact with.
AI-powered knowledge management systems are becoming central to organizational efficiency, with companies reporting 25% performance improvements when AI systems are properly integrated. Our code intelligence system extends this trend specifically to software development workflows.
Future-Proofing Development Workflows
As knowledge graphs continue to reshape AI workflows in 2025 and beyond, organizations that adopt graph-based approaches to code understanding will be better positioned to leverage emerging AI capabilities. Our proof of concept establishes the foundation for more sophisticated applications: automated refactoring, intelligent testing, and AI-powered architectural decisions.
Conclusion
The Knowledge Graph Contextual Intelligence System's proof of concept demonstrates that the future of code understanding lies in relationship-aware, AI-powered analysis. By combining the relationship modeling capabilities of graph databases with the natural language processing power of modern LLMs, we’ve created a system that bridges the gap between complex technical architectures and human understanding.
Our key findings show that graph-based code intelligence can reduce code comprehension time by up to 70%, enable accurate business impact analysis, and democratize technical knowledge across organizational roles. The modular, standards-based architecture ensures compatibility with existing tools while positioning organizations to leverage the rapidly growing graph database and MCP ecosystems.
The next phase involves expanding from proof of concept to production-ready implementation. This includes enhancing performance optimizations, developing industry-specific abstractions, and building comprehensive integration libraries for major development platforms.
The era of isolated, syntax-focused code analysis is ending. Organizations that embrace relationship-aware, graph-powered code intelligence today will gain significant competitive advantages in software development velocity, architectural decision-making, and business-technical alignment. The question isn’t whether this approach will become standard — it’s how quickly forward-thinking organizations will adopt it.
References
Throughout the preparation of this whitepaper, information and insights were drawn from a range of reputable sources, including research papers, articles, and resources. Some of the key references that informed the content of this whitepaper include:
- “Neo4j: The World’s Leading Graph Database” – Neo4j Inc
- “GraphRAG: Graph-enhanced Retrieval-Augmented Generation” – Various Authors
- “PocketFlow: A Minimalist LLM Orchestration Framework” – GitHub Repository
- “Amazon Neptune – Fully Managed Graph Database” – Amazon Web Services
- “LangChain: Building Applications with LLMs” – LangChain Team
- “MCP Protocol: Model Context Protocol for AI Agents” – Open-Source Initiative
- “The Rise of Knowledge Graphs in AI Workflows” – Gartner Research
These references provided the foundation upon which the discussions, insights, and recommendations in this whitepaper were based.






Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!