Artificial Intelligence




RAG for Legacy Databases Text2Query with LLM-Powered Self-Query Retrieval
This whitepaper explores the approach which leverages large language models to implement Retrieval-Augmented Generation (RAG) for legacy databases without native vector support. The system employs a Text2Query paradigm where an LLM analyzes user queries and database metadata (schema, categorical values, range constraints, and business rules) to generate appropriate SQL or other database queries. Multiple queries may be generated to obtain comprehensive context from different database perspectives. The retrieved structured data is then processed by the LLM to perform final analysis and generate contextually relevant responses. This method bridges the semantic gap between natural language user intent and rigid database structures without requiring database architecture modifications or vector embeddings.
Insights
Modern enterprises face a significant challenge: they possess vast amounts of valuable data locked within legacy database systems that cannot be easily queried using natural language or integrated with modern AI systems. Instead of modifying the underlying database architecture, this white paper speaks about leveraging large language models (LLMs) to:
- Analyze and understand database metadata (schema, relationships, constraints)
- Interpret natural language queries in the context of available data
- Generate appropriate database queries (SQL, NoSQL, etc.) to retrieve relevant information
- Process and synthesize the structured results into coherent, contextually relevant responses
By implementing Text2Query with LLM-Powered Self-Query Retrieval, enterprises can modernize their data interaction capabilities without the disruption and expense of wholesale system replacement.
Introduction
Many organizations rely on legacy database systems (like relational or NoSQL databases) that store critical business information. However, accessing this data typically requires knowledge of specific query languages (e.g., SQL) and a deep understanding of the database structure (schema, relationships). This creates a significant barrier for non-technical users who need to ask questions and get insights from this data using natural language.
Retrieval-Augmented Generation (RAG) has emerged as a powerful technique for LLMs to answer questions using external knowledge sources, reducing errors, and providing up-to-date, domain-specific information.
However, applying traditional RAG methods to structured legacy databases is challenging because they often require data to be converted into vector embeddings, which these databases don't natively support and can be impractical for large, complex schemas.
There is a need for a solution that allows natural language querying of these legacy systems without requiring costly database overhauls or relying on vector embeddings.
The Legacy Database Challenge
While RAG has proven effective for unstructured data (documents, articles, web content), its application to structured legacy databases presents unique challenges:
- Vector Embedding Requirement: Most RAG implementations rely on vector embeddings for semantic search, which legacy databases do not natively support.
- Schema Complexity: Enterprise databases often contain complex schemas with hundreds or thousands of tables and relationships that are difficult to represent in vector space.
- Query Constraints: Business rules, access controls, and data integrity constraints in legacy systems cannot be easily represented in typical RAG mechanisms.
The Text2Query Opportunity
The Text2Query paradigm represents an alternative approach that leverages the reasoning capabilities of large language models to bridge the gap between natural language queries and database queries. Rather than transforming database contents into vectors, this approach focuses on LLMs to generate appropriate database queries based on:
- Database metadata (schema, relationships, constraints)
- User query intent and context
- Business rules and access patterns
By focusing on query generation rather than data transformation, Text2Query offers a path to RAG implementation for legacy databases without the need for architectural overhauls or vector embeddings.
Industry Context
The financial services industry, including banks, insurance companies, and investment firms, stands to benefit significantly from this approach. These organizations often operate on legacy systems with vast amounts of structured data. Enabling natural language access to this data can improve customer service, risk analysis, compliance reporting, and operational efficiency.
Responsible AI Considerations
This approach supports enterprise scalability by handling large datasets and batch processing. It also enhances security by preserving existing database access controls and introducing LLM-specific safeguards, ensuring compliance with enterprise governance policies.
Problem Statement – Real -World Example
A large European banking client faced challenges in enabling business analysts to query for legacy financial databases. These databases required complex SQL knowledge and had rigid schemas, making it difficult for non-technical users to retrieve insights. The semantic gap between natural language and structured queries led to delays in decision-making and increased reliance on technical teams. Existing approaches like Vector DB are risky, expensive, inflexible and bring high chances of hallucinations in case of ambiguous or long context conversations.
The core challenge is the semantic gap between how humans ask questions (natural language) and how legacy databases store and retrieve data (structured queries).
- Natural Language is Flexible, Database Queries are Rigid: Users ask questions contextually, sometimes ambiguously ("recent top customers"). Databases require precise instructions (specific tables, fields, joins, filters, date ranges like SELECT customer_id FROM orders WHERE order_date BETWEEN '2024-01-01' AND '2024-03-31' GROUP BY customer_id HAVING SUM (order_value) > 10000).
- Database Knowledge is Required: Effective querying demands understanding the database schema (tables, columns, relationships), data types, and business rules encoded within. Most users lack this knowledge.
- Complex Questions Need Complex Queries: Answering business questions often involves combining data from multiple tables, applying specific calculations, or comparing data across time periods, requiring sophisticated query construction.
Figure 1: Solution idea - Process flow
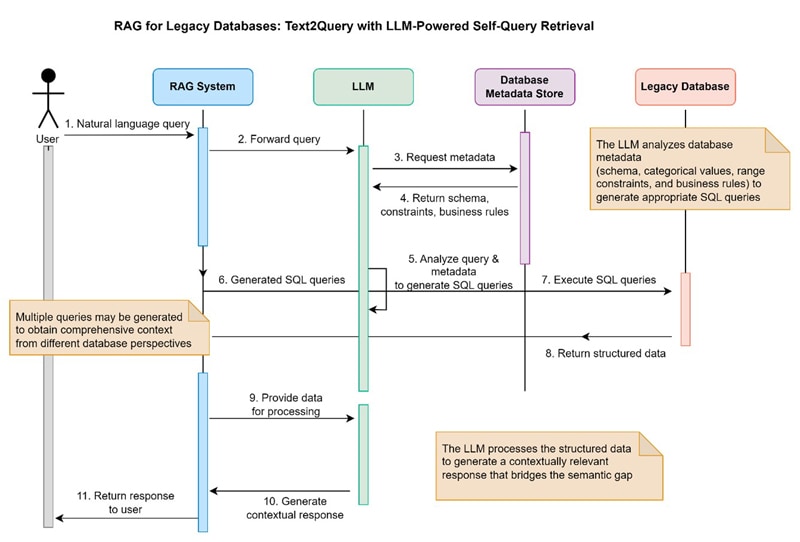
Present Limitations
While the Text2Query approach provides significant benefits for accessing legacy databases through natural language, several important limitations should be acknowledged:
1. Query Complexity Limitations
- Nested Analytical Queries: Highly nested analytical queries with complex aggregations and window functions may not be generated correctly in all cases.
- Advanced Statistical Operations: Queries requiring advanced statistical operations (regression, correlation, etc.) may exceed the capabilities of the current generation system.
- Temporal Logic Complexity: Queries with complex temporal logic involving multiple time dimensions can be challenging to generate accurately.
Example of a challenging query:
"Show me the correlation between customer purchase frequency and average order value, segmented by acquisition channel, but only for customers who have made purchases in at least 3 different product categories over the past 2 years, excluding promotional purchases."
2. Schema Understanding Constraints
- Highly Normalized Schemas: Extremely normalized schemas (5NF+) with dozens of related tables for a single business entity can exceed the context window or relationship tracking capabilities.
- Dynamic Schemas: Databases with frequently changing schemas require constant retraining or updating of metadata repositories.
- Sparse Documentation: Legacy systems with minimal documentation and unclear naming conventions reduce accuracy of query generation.
- Entity-Attribute-Value Models: EAV and other highly flexible schema designs present challenges for the query generation.
3. LLM Limitations
- Context Window Constraints: Large database schemas may exceed the context window limitations of current LLMs.
- Reasoning Depth: Multi-step reasoning required for complex queries may exceed the reasoning capabilities of some LLMs.
- Limited Feedback Incorporation: Current LLMs have limited ability to incorporate feedback from failed queries into their reasoning process.
4. Performance Considerations
- Query Latency: Complex queries requiring multiple LLM calls may exceed user expectations for response time, particularly in interactive scenarios.
- Database Load: Inefficiently generated queries may place excessive load on production database systems if not properly managed.
- Resource Requirements: LLM inference requirements may be substantial for high-throughput enterprise deployments.
Proposed Solutions and Future Improvements
1. Query Complexity Limitations:
- Incorporates specialized query generation modules for analytical and statistical operations.
- Use hybrid systems combining LLMs with rule-based engines for complex logic.
2. Schema Understanding Constraints:
- Implement schema summarization and visualization tools to aid LLM comprehension.
- Use schema versioning and automated metadata refresh pipelines.
3. LLM Limitations:
- Employ retrieval-augmented techniques to extend context windows.
- Integrate feedback loops and reinforcement learning for continuous improvement.
4. Performance Considerations:
- Optimize query generation with caching and query planning strategies.
- Use dedicated inference infrastructure and load balancing for scalability.
5. Reducing chances of hallucinations makes the response more transparent and contextual.
Conclusion
This Text2Query approach offers significant advantages:
- Unlock Legacy Data: Makes valuable data in existing systems accessible via natural language.
- Non-Invasive Integration: Works with current database infrastructure without requiring costly migrations, architectural changes, or system downtime.
- No Vector Embeddings Needed: Avoids the complexity, cost, and synchronization challenges associated with creating and maintaining vector representations of database content.
- Preserves Security & Governance: Operates within existing database security protocols, roles, and access controls. Adds LLM-specific safeguards.
- Reduces Technical Bottlenecks: Empowers non-technical users to perform self-service data analysis, freeing up technical staff.
- Accelerate Insights: Speeds up the process of getting answers from data, leading to faster decision-making.
- Adaptable: Can be tailored with metadata to understand specific business domains and database nuances.
The Text2Query approach provides a pragmatic path forward for organizations seeking to modernize data access without the disruption and expense of wholesale system replacement. By bridging the gap between natural language and legacy databases, organizations unlock the full potential of their existing data assets while laying the groundwork for more advanced AI-driven data systems in the future.
As data continues to grow in both volume and strategic importance, the ability to access and leverage that data through natural interfaces will become an increasingly critical competitive advantage.






Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!