Experience




Mainframe Disaster Recovery requires Constant attentiveness in this ever-changing landscape
This whitepaper explores the, about the cases where application in mainframe environments fails at the time of Disaster recovery and ways to prevent those cases and explains best practices and industry advancements.
Insights
- This whitepaper examines cases where application in mainframe environment fails at the time of disaster recovery.
- Steps to prevent those failures
- Best practices maintained across the industry
- Industry advancement in mainframe Disaster recovery.
Introduction
With over five decades of evolution, the IBM Z Mainframe Disaster Recovery (DR) requirement/associated processes have progressed and transformed accordingly. While Fault tolerance is a defining feature of mainframes, achieving true business continuity requires a comprehensive multi-layered strategy that delivers the targeted benefits.
Mainframe has a built-in Culture of Resilience having measurable business impact and boasts a layered architecture specifically designed for redundancy, offering a quantifiable advantage in terms of business continuity.
However, mainframes are not immune to disruption. Natural disasters, software glitches, Hardware failures and cyberattacks can all unsettle mainframe operations and pose serious risk to business continuity. It is essential to build a comprehensive DR plan and perform periodically to recover swiftly and effectively.
Mainframe Disaster recover strategy
Mainframe DR strategy is critical to ensure the continuity of critical business operations in the face of unexpected disruptions. This involves data replication, system recovery, and application restoration to ensure business continuity. Business continuity and disaster recovery (BCDR) are intertwined processes that ensure an organization can continue operating during and after a disruption or disaster, minimizing downtime and impact.
Business continuity
Business continuity envisions the aspects an organization will take to ensure the swift restoration of business activity following a crisis. It considers a broad approach and aims to ensure an organization can face as broad a range of threats as possible.
Detailed key strategies
Provide the details as per the White paper here
a) Comprehensive Risk assessment based on business impact analysis
A tailored comprehensive risk assessment based on business impact analysis and comprehensive asset inventory and recovery objectives is performed. DR plan involves a comprehensive assessment of possible threats and their implications for business continuity.
b) Defining RTO & RPO
- Recovery Time Objective (RTO) refers to the maximum acceptable duration and service level within which systems must be restored after a disruption to prevent significant impact on business continuity.
- Recovery Point Objective (RPO) measures the maximum time window in which data loss is tolerable following a disruption. It determines how much data can be lost without significant impact.
| Core DR Terms KPI | Definition | Benchmark |
|---|---|---|
| Recovery Time Objective (RTO) | Maximum acceptable duration to restore operations after a disruption. | Varies by system criticality. For mission-critical systems, RTO is often < 4 hours; for less critical systems, < 24 hours. |
| Recovery Point Objective (RPO) | Maximum time window in which data loss is tolerable following a disruption | For financial or transactional systems, RPO is typically < 15 minutes; for batch systems, < 4 hours. |
| Mean Time to Recovery (MTTR) | Average time taken to restore a system after a failure. | Should be equal to or less than RTO. If MTTR > RTO, the DR plan is underperforming. |
| Recovery Time Actual (RTA) | Actual time taken during DR testing or real events. | Should consistently meet or beat the RTO target. |
| Recovery Confidence Level (RCL) | A subjective but quantifiable measure of confidence in recovery success, often based on test results. | Aim for ≥ 90% confidence based on successful DR tests and simulations. |
| System Uptime Percentage | Percentage of time systems are operational. | Target ≥ 99.99% uptime for critical systems. |
| Backup Success Rate | Percentage of successful backups over a period. | ≥ 98% success rate is considered healthy. |
| Incident Resolution Time | Time taken to resolve DR-related incidents. | Should be < 2 hours for high-priority incidents. |
| Plan Test Results | Success rate of DR plan tests. | 100% success in test execution; ≥ 90% in recovery validation. |
| Compliance Audit Outcomes | Results from regulatory or internal audits. | No major findings; full compliance with standards like ISO 22301, NIST SP 800-34, etc. |
c) Identify the critical business process and application
Conduct regular asset inventories to identify all hardware, software, IT infrastructure, applications, portfolios, and other resources essential to the organization's critical business operations.
d) Data backup and data recovery methods
Creating copies of data and establishing procedures to restore it in case of loss or damage. Strategies like full, incremental, and differential backups (utilizing both disk and tape storage), Cold/Warm/Hot site, On-Site/Off-Site, 3-2-1 Strategy, Immutable storage, Cloud storage and employing techniques like object-level or system-level recovery are thought through and considered.
e) Establishing communication channels/protocols and assigning responsibilities.
Establish channels for alerting stakeholders and coordinating recovery efforts. Clearly define who is responsible for each task during recovery. Keep key contacts, vendor information, and system configurations readily available.
f) Test and reiterate the plan
Regular testing of the disaster recovery plan is essential to validate its effectiveness and ensure readiness. Update the plan based on test results and evolving threats. Regularly review and update the disaster recovery plan based on testing results, changes in technology, and evolving business needs. Ensure the plan remains relevant and effective over time.
| Key Stake holder | Roles | Responsibilities |
|---|---|---|
| Disaster Recovery Coordinator / Manager | Oversee the entire DR process. |
|
| Infrastructure Team | Manages hardware, network, and system configurations. |
|
| Application Owners / Portfolio Managers | Responsible for specific business-critical applications. |
|
| Database Administrators (DBAs) | Manage data integrity and recovery. |
|
| Security Team | Safeguard systems and data during and after a disaster. |
|
| Business Continuity Team | Align DR with broader business continuity goals |
|
| Testing & QA Team | Validate DR procedures and outcomes. |
|
| Executive Sponsors / Leadership | Provide strategic direction and funding. |
|
| Vendors / Third-Party Providers | Support infrastructure, software, or DRaaS. |
|
Challenges and consideration for effective Disaster recovery strategies
Effective risk assessment
Organization has DR plan created based on the business impact risk assessment over the period. However, many DR plans have not been effectively reassessed during these periods. In some cases, organization falls short in addressing the ability to recover from low-probability or unlikely disaster scenarios. To have truly effective DR strategies, Organization must periodically assess the business impact and as well as with consider the full range of potential impacts, including those stemming from remote or improbable events. Budget constraint Disaster recovery solutions can be expensive for smaller organizations operating with limited financial resources. Despite the upfront costs, the financial impact of downtime and data loss often surpasses the investment needed for a robust disaster recovery plan.
| Disaster & Impact | Estimated Cost | Consequences | Lessons learnt |
|---|---|---|---|
| CrowdStrike-Microsoft Global IT Outage (2024) - A faulty update to CrowdStrike’s Falcon software caused a global crash of 8.5 million Windows devices | Over $5.4 billion in damages | Grounded flights, halted banking systems, and hospitals reverting to paper-based operations Massive reputational damage and operational paralysis. |
Even top-tier cybersecurity tools can fail. Investing in redundancy, failover systems, and incident response simulations is far less costly than the fallout from a global outage |
| Change Healthcare Ransomware Attack (2024) - One of the largest healthcare breaches. | affecting over 100 million individuals | Operational shutdowns and data hostage scenarios. Regulatory scrutiny and long-term reputational harm. |
A comprehensive backup and recovery strategy can neutralize ransomware threats. Investing in data resilience and clean restore points is critical for continuity |
| UniSuper Google Cloud Account Deletion (2024) | A $135 billion pension fund temporarily lost access to data for 640,000 members | Recovery was possible only because of a third-party backup | SaaS data protection is a shared responsibility. Investing in external backup partners ensures compliance and operational continuity |
Testing and maintenance
To ensure minimal business disruption, disaster recovery plans must be consistently tested and maintained, verifying that failover and failback processes perform as expected or better. However, many organizations face challenges in dedicating time and resources to regular testing, leaving them exposed to unforeseen events.
Staff training and expertise
Sustaining a workforce proficient in mainframe computing is becoming increasingly difficult, as such expertise is less common in today’s IT landscape.
Mainframe DR failures based on industry experience
There were many industry cases where DR failed, here’s a detailed look at some common reasons for DR failures
Case 1
The Organization believed that a robust DR plan, including well documented procedures and sufficient resources, was in place to handle any major outages or failures. However, a recent DR event revealed significant gaps, resulting in extended downtime and business impact.
Incident Summary
An upgrade involving Db2 patches was applied to the production system. No issue surfaced in lower environment. Db2 system was down in production due to the patches. A DR recovery process was initiated to restore the application to its latest state. However, application recovery time far exceeded the planned window, causing significant business down time and operational disruption.
Key Root causes identified
- Inexperienced personnel and not aware of DR process/steps.
- Not able to catch the Db2 patching upgrade issue in lower environment as the lower environment was not like production.
- Outdated Documentation (was not revised in the recent period)
Case 2
Disaster occurred at the organization’s primary data center, triggering the need for a full disaster recovery process. During this process, the Db2 database backup was found to be corrupted, which caused significant delays and partial data loss.
Incident summary
The recent Db2 backup was corrupted and unusable for recovery. DR team restored the system using the most recent good backup along with the archived logs. However, validation of the backup and recovery process took longer than expected, resulting in extended recovery time affecting business operations.
Key Root causes identified
- There were some software configuration issues and as well as improper backup procedures followed.
- Testing of backup creation and recovery from backup were not properly conducted.
- Incomplete execution of DR procedures.
Case 3
Organization had planned mainframe maintenance activity. Failover failed and led to significant downtime.
Incident summary
During a planned maintenance window for mainframe hardware/software activities, the organization attempted to initiate a failover to the backup system. However, the failover mechanism did not function as expected, resulting in service disruption. When the primary mainframe system was restored, lost time and capacity constraints forced the organization to prioritize the application workloads, causing downtime for several low priority applications.
Key Root causes identified
- These kinds of scenarios were not predicted in the risk assessment and DR plan not included for scenarios like this case.
- Asset inventory is not captured or matured enough to handle the situation.
Conclusion from Case studies
In the above DR failure cases the following best practices are not observed:
- Periodic risk assessment and re-evaluation of DR strategies
- Periodic DR plan revisit, test and update the respective documents
- Inventorying the assets regularly
Infosys Approach - Focusing on three key aspects in DR strategy
Mainframe Application recoverability assessment
Evaluates an organization's ability to restore critical mainframe applications and data after an outage or disaster. By focusing on how well individuals or groups of applications can withstand, recover from and adapt to failures or disruption, application resilience is evaluated and acted upon it accordingly. This involves the combination of DR strategies, primarily focusing on 3 key DR strategies.
Risk assessment, DR plan review, Asset inventory prioritization review.
Risk assessment:
Tailored Comprehensive periodic risk assessment is a key. It helps organizations understand their vulnerabilities and potential impacts, enabling them to develop effective recovery strategies. It involves recognizing possible threats, evaluating their probability and potential consequences, and strategically prioritizing resources to address them.
1. Identify Scope and Objectives
Determine the specific systems, data, and applications that are critical to the business and need to be protected during a disaster.
2. Identify Risks and Threats
Natural Disasters: Consider events like hurricanes, floods, earthquakes, or other weather-related incidents that could damage the physical location of the mainframe.
System Failures: Account for hardware, software, or network failures that could impact mainframe availability.
Human Error: Evaluate risks from accidental data deletion or other mistakes made by employees.
Vendor-Related Issues: Consider the impact of outages or failures at vendors who provide critical services or infrastructure.
Cyberattacks: Address vulnerabilities to cyber threats that could disrupt operations or data loss.
3. Analyze Risks and Impacts
Business Impact Analysis (BIA): Assess the potential financial, reputational, and operational consequences of different disaster scenarios.
Risk Assessment Matrix: Use a matrix to categorize risks based on likelihood and impact to prioritize remediation efforts.
Fig 1 :Example of color-coded risk assessment matrix
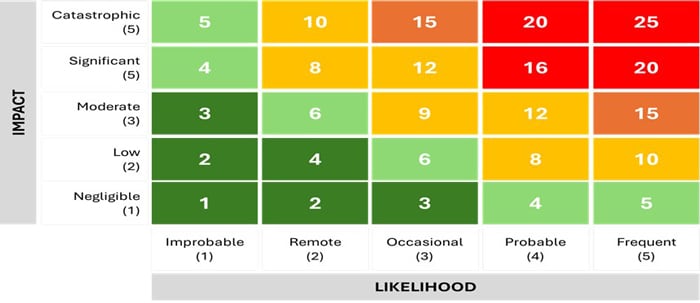
A risk assessment matrix offers a structured visual representation; a risk assessment matrix helps organizations evaluate and understand the severity and likelihood of various risks. Risks that fall into the green areas of the matrix might not require any action. Yellow and orange risks likely do, while in the red part need urgent actions.
Consider various scenarios depending on risk assessment matrix impact and likelihood occurrences.
4. Evaluate Risks and Controls
Identify Existing Controls: Review existing security measures, backup and replication procedures, and other safeguards.
Evaluate Control Effectiveness: Determine if existing controls are sufficient to mitigate identified risks.
5. Identify Gaps and Recommendations
Develop Remediation Strategies: Propose specific actions to address identified gaps, such as implementing new security policies, improving backup procedures, or investing in a new disaster recovery site.
6. Monitor and Review
Regularly Review the Plan: Periodically review the risk assessment and disaster recovery plan to ensure that it remains up-to-date and effective.
DR plan review
A DR (Disaster Recovery) plan review is a detailed measure to identify gaps, inconsistencies, and areas for improvement, ensuring it remains relevant and effective. It involves verifying the plan's accuracy and ensuring all participants understand their roles.
1. Effective documentation completeness:
Review the completeness and accuracy of the DR plan documentation. This includes procedures for data backup and recovery, system restoration, and communication protocols.
2. Infrastructure & Environment preparedness:
Validate the recovery site procedures. Validate the Encryption and decryption procedure. Validate the system configuration like LPAR images, IOCDS, system residence volumes can be copied at the DR site. Validate the Data replication tool like GDPS, PPRC (Peer to Peer Remote copy) and XRC (extended remote copy) usages. Validate Security network access to the DR site. Validate the IPL Procedure.
3. Application recovery readiness
Validate the application RTO, RPO, actual RTO and actual RPO compliance. Validate recovery instructions for CICS, IMS, DB2, MQ etc., documented for application. Validate transaction and batch jobs resume using checkpoint/ restart, or with backout logs, or with sync points. Validate the interfaces to the external system in the plan. Validate the batch schedule replication and restart ability at the DR site. Validate security databases sync and replication at DR site. Validate user credentials for DR site DR Testing validation Validate the Test frequency, Test types, Test documentation. Validate all the identified disaster recovery test scenarios. Validate after-action reviews and improvements tracked.
Disaster recovery test scenarios:
- Data Loss and Backup Recovery
- DR Test for Failed Backups
- Backup Verification for DR Testing
- DR Test for Hardware Failure
- Network Interruptions and Outages
- Remote likelihood scenario testing or Crunch scenario testing
Out of the six, five are common scenarios, generally involving in DR testing process. Sixth scenario focuses on evaluating a system or application under highly improbable, yet potentially impactful, conditions. For example: While trying to recover, failovers for some reason are not working on that occasion. And for some reasons, when there is a crunch in mainframe resource capacity, on what orders the application needs to be started. These may be a remote scenario, but risk assessment and DR plan should test it accordingly depending on various factors.
Asset inventory prioritization review
It is the process of ranking an organization's assets (Hardware/ Software/ Portfolio/ Application) based on their importance to business operations and the potential impact of their failure. This involves assessing and reviewing the criticality, vulnerability, resource requirements and prioritization of the assets. By implementing a robust asset inventory prioritization process, organizations can effectively manage their assets, minimize risks, and improve their overall security posture and the recovery process.
Asset prioritization table that ranks key assets based on their criticality, vulnerability, and resource requirements.

This table helps identify which components require the most attention during disaster recovery planning and prioritization.
Best Practices
1. Tailored Risk Assessment
A comprehensive disaster recovery plan starts with a thorough risk assessment. This meticulous process involves identifying critical applications and data, pinpointing potential threats (natural disasters, cyberattacks, power outages), and meticulously analyzing the impact of downtime on core business functions.
Based on this assessment, organizations can prioritize resources and tailor their disaster recovery strategy to achieve the most cost-effective solution. For instance, an organization heavily reliant on real-time transactions might prioritize synchronous data replication for maximum consistency, even if it comes at a slightly higher cost. Another organization focused on batch processing might opt for asynchronous replication for better performance and a more cost-effective approach.
By conducting a thorough risk assessment, organizations can strike a balance between achieving the desired level of business continuity and controlling disaster recovery expenses. This ensures they are investing in the most appropriate solutions to mitigate risks and safeguard their critical operations.
2. Failover Clustering: Increased Uptime and Enhanced Customer Satisfaction
Clustering software enables the creation of redundant server groups. If a primary mainframe encounters a problem, a secondary machine seamlessly takes over processing, minimizing downtime. This approach ensures applications remain available to users even during hardware failures.
Imagine an e-commerce platform experiencing a surge in traffic during a sales event. With failover clustering in place, the mainframe can seamlessly scale up to meet the demand, preventing website crashes and ensuring a smooth customer experience. This results in improved customer satisfaction, increased conversion rates, and ultimately, greater revenue growth.
3. High Availability Tools: Proactive Monitoring for Reduced Downtime and Improved Efficiency
Software tools can automate failover processes and provide real-time system monitoring. These tools allow administrators to proactively identify and address potential issues before they escalate into outages. Proactive monitoring empowers IT teams to nip problems in the bud, preventing disruptions to critical business functions and reducing the overall cost of downtime. Imagine a manufacturing plant relying on a mainframe to manage its production lines. By proactively identifying and addressing system anomalies, high availability tools can prevent production delays and ensure optimal operational efficiency.
Automation is central to modern DR strategies, reducing manual intervention and improving recovery speed and accuracy. Key tools include:
IBM GDPS (Geographically Dispersed Parallel Sysplex):
A comprehensive suite for automating storage management, remote copy configuration, and failover across sites. It supports synchronous and asynchronous replication and integrates with IBM Z Cyber Vault for cyber resilience.
Adaptigent Automation Suite:
Offers intelligent orchestration, AI-driven event handling, and Robotic Process Automation (RPA) for legacy systems. It enables predictive system tuning, anomaly detection, and self-healing infrastructure.
BMC AMI Ops Automation:
Provides real-time monitoring, automated remediation, and integration with hybrid cloud environments.
Broadcom CA OPS/MVS:
Automate system operations and recovery tasks, ensuring high availability and compliance.
These tools enable features like autonomous fault recovery, environment-agnostic workflows, and encryption lifecycle management, which are critical for resilient DR architectures
4. Leveraging cloud for Data Resilience
Cloud computing has transformed disaster recovery by offering scalable, cost-efficient solutions. Mainframe environments can leverage cloud-based approaches in multiple ways to enhance recovery capabilities
- Scalability
- Cost efficiency
- Geographic Redundancy Considerations for cloud-based disaster recovery
- Data Security
- Vendor Selection
- Connectivity
5. Periodic Inventorying the assets
To ensure an effective Disaster Recovery Plan (DRP), it's essential to have a clear understanding of all your enterprise assets. Conduct regular inventories to accurately identify hardware, software, IT infrastructure, and any other critical components your organization depends on for key business operations. Periodically classify criticality of the application/key module order accordingly.
Future trends in mainframe disaster recovery
Key trends that are expected to define the future of mainframe disaster recovery strategies
1. Hybrid Cloud Integration
Mainframes are increasingly being integrated with hybrid cloud environments to enhance flexibility and scalability. Disaster recovery solutions are leveraging cloud-based storage and computing resources to replicate mainframe workloads, enabling faster recovery times and reducing dependency on physical infrastructure. This trend supports cost-effective DR strategies and facilitates geographic redundancy.
2. Automation and Orchestration
Automation is becoming central to disaster recovery planning. Tools that automate backup, replication, failover, and recovery processes are reducing human error and improving recovery time objectives (RTOs). Automate data replication in conjunction with traditional tape restoration wherever possible. Orchestration platforms are enabling seamless coordination across mainframe and distributed systems, ensuring consistent and reliable recovery workflows.
3. AI and Predictive Analytics
Artificial Intelligence (AI) and machine learning are being used to predict potential system failures and optimize DR strategies. Predictive analytics can identify patterns and anomalies in system behavior, allowing proactive measures to be taken before a disaster occurs. These technologies also help in simulating disaster scenarios and refining recovery plans.
Artificial Intelligence (AI) and Predictive Analytics are revolutionizing disaster recovery (DR) strategies in mainframe environments. These technologies enable organizations to move from reactive recovery models to proactive and intelligent resilience planning. Key Feature advancements include Automated Root Cause Analysis, Intelligent Backup and Recovery Optimization, Dynamic Resource Allocation, Enhanced Cyber Resilience, Continuous Improvement Through Feedback Loops
Example Tools:
- IBM Z AIOps: Uses AI to detect anomalies, correlate events, and recommend remediation actions.
- BMC AMI Ops Insight: Applies machine learning to identify performance degradation and suggest corrective measures.
- IBM Z Cyber Vault: Integrates AI to monitor backup integrity and detect signs of compromise, enabling rapid recovery from cyberattacks.
4. Cyber Resilience and Zero Trust Architecture
With the rise in ransomware and other cyber threats, disaster recovery is increasingly focused on cyber resilience. Mainframe DR strategies are incorporating Zero Trust principles, ensuring that every access request is verified and monitored. Immutable backups and air-gapped storage are becoming standard practices to safeguard data integrity during recovery.
5. Continuous Data Protection (CDP)
CDP is gaining traction as a method to ensure minimal data loss. Unlike traditional backup methods, CDP captures every change made to data in real-time, allowing recovery to any point in time. This is particularly valuable for mainframe environments where transaction volumes are high, and data accuracy is critical.
6. Compliance-Driven DR Enhancements
Regulatory requirements are influencing the design of DR strategies. Industries such as finance and healthcare are adopting more rigorous DR protocols to meet compliance standards. Future DR solutions will increase including automated compliance reporting and audit capabilities.
7. Colocation
Colocation is placing mainframe hardware and systems in a third-party data center that supplies essential infrastructure—such as power, cooling, connectivity, and physical security—while maintaining operational control. This model is gaining traction among organizations seeking to ensure business continuity without the financial and logistical burden of managing a secondary data center. Example: Maintec Technologies offers dedicated mainframe colocation services.
8. Mainframe-as-a-Service (MFaaS)
The emergence of MFaaS is transforming how organizations approach disaster recovery. By outsourcing mainframe operations to specialized service providers, businesses can leverage built-in DR capabilities, including geographic redundancy, high availability, and managed recovery services.
Conclusion
Mainframe remains an integral part of the IT landscape. Moving forward, planners must take a more active role in mainframe strategy and present disaster recovery requirements and options with greater business acumen to effectively develop strategies that support business continuity.
Organizations need to be vigilant towards the mainframe legacy application DR activity and have regular checks/assessment as with the above cases.
As technology continues to evolve, organizations must refine their mainframe disaster recovery strategies to address emerging challenges and capitalize on opportunities for enhancement. Ultimately, an organization's resilience is defined by its ability to recover from disruptions, making the mainframe disaster recovery a vital pillar of success in today’s digital landscape.
References
- Mainframe: Disaster Recovery Demands Constant Vigilance - Dez Blanchfield, May 2024
- MAINFRAME DISASTER RECOVERY STRATEGY - Christoper Tozzi 2019
- Disaster Recovery Best Practices – Broadcom team 2024
- MAINFRAME DISASTER RECOVERY PLANNING - JON WILLIAM TOIGO 2010






Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!