API, Microservices




Kafka with Microservices
This whitepaper explores how a Kafka-centric architecture improves microservice communication. One of the traditional approaches for communicating between microservices is through their REST APIS. However, as your system evolves and the number of microservices grows, communication becomes more complex and the architecture might start resembling our old friend spaghetti anti-pattern, with services depending on each other or tightly coupled, slowing down development teams. This model can exhibit low latency but only works if services are made available. To overcome this design disadvantage, new architectures aim to decouple senders from receivers, with asynchronous messaging.
Insights
- As part of organization digital transformation microservices adoption grows, event-driven architectures become essential for scalability etc. Kafka plays significant role in asynchronous communication between microservices which improves performance and decreases the dependencies.
- In a Kafka-centric architecture, low latency is preserved with additional advantages like message balancing among available consumers and centralized management.
- This white paper examines the concepts of Kafka and how Kafka can communicate with microservices.
Introduction
There is a lot of buzz around microservices and Apache Kafka lately. They can help improve the performance and scalability of our systems. In this, we want to focus on using Kafka in microservices, how it can help us. We will explore some of the benefits of using Kafka in this context and show how to get started with it.
Characteristics of API’s and Messaging
API ‘s has existed since the beginning of computers; APIs have been repurposed to refer to HTTP REST-based services. REST (representational state transfer) is a commonly used concept that provides access to resources using standard HTTP operations such as GET, PUT, POST, or DELETE.
Messaging encourages a decoupled architecture, where an intermediary - often referred to as a messaging provider - is placed between two applications, systems, or services. The messaging provider facilitates communication between the sender and receiver of messages and provides many benefits such as reliable delivery, workload balancing, and security.
Examples of Messaging protocols include:
Apache Kafka
| Characteristic | API | Messaging |
|---|---|---|
| Interaction Style | HTTP is synchronous. Each request message has a corresponding response that is an acknowledgment of the request message. This makes request/response solutions easy to implement. | Messaging is asynchronous, and allows a full range of interaction patterns, including fire and forget, where requesting messages do not have corresponding responses; request/response where each request message has a corresponding response; and publish/subscribe where applications, systems, or services can register for messages on a defined topic. The messages are forwarded to all subscribers when publishers emit events. |
| Application Usage | Ubiquitous. Almost all companies have IT infrastructures that support HTTP traffic, and most programming languages provide built-in support for HTTP. | Simplified application development. Messaging frees you from coding complex delivery mechanisms to assure messages are not lost, freeing you to focus on business logic. |
| Coupled | Simple. Communication flows directly from the requester to the providing service (unless the architecture deliberately introduces intermediaries that control the communication). | Decoupled. The messaging provider acts as a shock absorber between applications, protecting the messages. If the server or receiving application goes down, or it is too busy to process more requests, the message can wait in the messaging provider until the systems are up and it can be delivered. |
What are Protocols?
The term protocol is often used in news reporting to formalize interactions between officials and heads of state. It defines a set of rules and conventions that structure human interactions during talks and negotiations. Successful outcomes depend on all parties adhering to the correct protocol(s). Get something wrong and talks and can break down, with focus shifting quickly away from a shared goal and onto the frantic efforts needed to recover the situation.
In computing, we use the term protocol in much the same way. A protocol is just a set of rules that computers follow, allowing them to interact with each other, and with the outside world, in some predictable, deterministic way.
Some most commonly used Protocols:
- Rest (Representational State Transfer)
- SOAP (Simple Object Access Protocol)
- GraphQl
- gRPC (gRPC Remote Procedure Calls)
Some most commonly used Messaging Protocols:
- WebRTC- Web Real-Time Communication
- WebSocket
- XMPP- Extensible Messaging and Presence Protocol
- MQTT- Message Queuing Telemetry Transport

Apache Kafka
Apache Kafka is a distributed stream processing platform with high resilience and fault tolerance. This is obtained by using numerous clusters of computing nodes in distributed system co-ordination amongst which is maintained by another Apache platform called zookeeper.
n simpler words, it takes data from producers and streams them to consumers.
Microservices
Microservices are an architectural and organizational approach to develop software applications as an independent and small services which communicate with each other over a network. These are loosely coupled and deployed independently.
How Kafka can help with microservices
At a prominent level, Kafka can help with microservices in a few ways.
First, Kafka can help you handle communication between services. It provides a publish-subscribe messaging system that makes it easy to send messages between services. This can be helpful for things like updating data across multiple services or notifying other services about changes in state.
Second, Kafka can help improve performance and scalability. By using Kafka, each service can operate independently of the others, which can improve performance and scalability. Additionally, Apache Kafka's distributed nature means that it can handle large volumes of data without any problems.
Finally, Kafka is fault-tolerant, meaning that it can continue operating even in the event of a failure. This is important in microservices architecture, where individual services can fail without affecting others.
Design pattern for Kafka-based microservices communication
Design patterns can be employed when integrating Kafka within microservices for efficient communication.
- Event Sourcing: In this design pattern the state changes in an application are stored as a sequence of events. It keeps a history of all changes as a series of events instead of storing just the current state of entity. It is possible to rebuild the state of the entity by replaying the events. Kafka can be an event store.
- CQRS (Command Query Responsibility Segregation): CQRS separates write(commands) and read (queries) operations for a data store. In traditional architectures, the same model is used for both read and write operations. This separation allows more scalability and flexibility in handling complex scenarios. Kafka’s strength in distributed messaging and event sourcing aligns with CQRS pattern.
- Request-Reply Pattern: While Kafka typically operates in an asynchronous, it is possible to implement synchronous request-reply interactions by using specific Kafka features such as request topics, correlations IDs, reply topic. Each request can be sent to a specific topic, and the response can be sent back to a reply topic.
- Event-Driven architecture (EDA): This architecture enables microservices to communicate with each other through events. Topics can be used to implement this event-driven architecture. Each topic can represent an event and services can subscribe to those topics.
Kafka Cluster
The Kafka cluster is a combination of multiple Kafka nodes. On top of Kafka nodes, we need to deploy the multiple Kafka services like Kafka Broker, Kafka consumer, Kafka Producer, Zookeeper, etc. In the Kafka cluster, we are getting multiple functionalities like a failure, replication, data high availability, multiple partition support, etc.
In simple terminology, we can say that the Kafka Cluster is the combination of multiple brokers and distribute the data on multiple instances. In the Kafka cluster, the zookeeper is having an extremely critical dependency. Here, the zookeeper is playing a role as a synchronization service and manage the distributed configuration. Zookeeper Server also plays a significant role in terms of coordinator interface in between the stack of Kafka brokers and consumers.
Figure 1. Basic Kafka cluster diagram
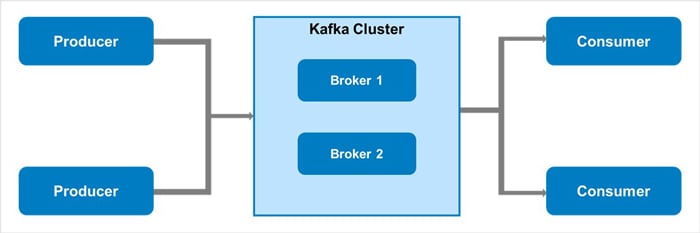
Kafka Broker
The main component for this streaming of data is the Kafka broker. The Kafka broker manages all requests from all clients (both producers and consumers as well metadata). It also manages replication of data across a cluster as well as within topics and partitions.
Kafka Topics
A Kafka topic is a grouping of messages that is used to organize messages for production and consumption. A producer places messages or records on to a given topic, then a consumer reads that record from the same topic. A topic is further broken down into partitions that house a number of records each identified as a unique offset in a partition log.
Zookeeper
It was originally developed to manage and streamline big data cluster processes and fix bugs that were occurring during the deployment of distributed clusters.
It is a centralized service that provides distributed coordination, names and configuration information maintenance for applications that are executing in a distributed environment.
Apache Kafka makes use of Zookeeper to manage the following:
- In a Kafka Zookeeper cluster, Zookeeper tracks broker membership, topic configuration, leader selection and metadata related to Kafka topics, brokers, and consumers.
- It stores the configurations of Kafka topics, stores the configurations of topics, and chooses leaders for each partition.
Figure 2: Basic Zookeeper diagram with Kafka cluster
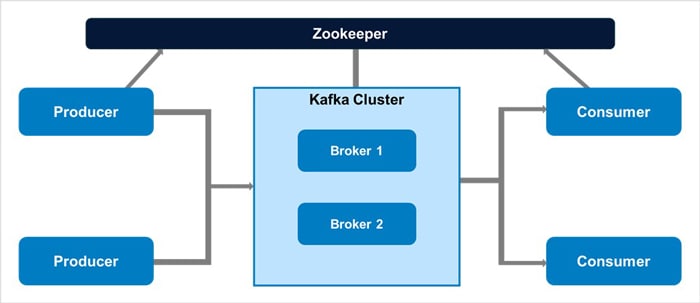
Kafka Producers
Producers will write the data to topics and topics are made of partitions. Producers know which broker receives the data. If there is any failure in the partition, producers know it and recovers automatically. Producers send data across all partitions using certain mechanisms. Message Keys are used, in which producers have keys in their messages and key can be any datatype like string, number etc.
So, if the key is null then the data is sent to a round robin fashion. Which means the data will go into partition 0, followed by next partitions ensuring load balancing. If there is a key sent with the message, then the message with same key will go to same partition. This will maintain order of messages in a specific field.
Delivery semantics
Delivery Semantics define how the streaming platforms guarantee the delivery of events from source to destinations. the three-delivery semantics are.
- At-most-once: In this approach message should be delivered maximum one time, where no message should be delivered twice, even though the message is lost. Here acks is set to 0 (acks=0), where the producer does not confirm whether the message is delivered to broker. Producer does not wait for any response.
- At least-once: In this approach multiple messages can be delivered, but there should not lose of messages. Producer ensures that all the messages are delivered, even though there is a duplication of messages. Here acks is set to acks=all (with min.insync.replicas configured), where producer confirms the message is delivered to broker. Producer waits for response and if there is no response for the message sent, it will again send the message.
- Exactly-once: In this approach only one message should be delivered at once without any loss of message. This requires enabling the idempotent producer (enable.idempotence=true) and transactions for atomic writes; acks=all is a prerequisite for durability but is not sufficient on its own for exactly-once. Producer waits for the response for the message sent.
Kafka Consumers
Consumers are used to fetch the data from the topic. Consumers will know from which topic and partition to read from. If there is any failure consumer will automatically recover from it. Grouping of consumers is called consumer group , if the consumers have subscribed to same topic, each consumer will get different partitions in which the message will not be same. Deserializer is needed for consumer to read the messages from Kafka as it transforms bytes to data.
Apache Kafka Raft (KRaft)
Even though zookeeper acts as a controlling mechanism for Kafka architecture there are certain drawbacks including complicated deployment and security and scalability issues.
Apache Kafka Raft (KRaft) was introduced to reduce this Kafka dependency on zookeeper. KRaft is based on Raft consensus protocol, and it consolidates responsibility of metadata into Kafka itself which eliminates the need to split it into two different systems.
In KRaft architecture a few nodes are identified as potential controllers, and one controller is elected as Kafka controller through Raft consensus protocol. The concept of Raft based quorum controller helps to manage the metadata of the cluster in a scalable way. The usage of KRaft helps to improve the operational aspects of Kafka including the below.
- Improved scalability
- Simplified deployment
- Unified administration
- Instantaneous failover
Interaction with Microservices
In the Microservice architecture, producers and consumers can be used to,
Publish Events: Services can publish the events or messages to the Kafka topics of the application.
Subscribe to Events: Services can subscribe to applicable Kafka topics to receive and process events.
Message Ordering
Kafka ensures that the messages sent within a partition are in order. Messages will be appended to the log in the order which they are sent. Consumer read these messages in the same order which they sent.
Types of Testing
| Types | Description |
|---|---|
| Unit testing | Unit tests typically run on a single process and do not use network. |
| Integration testing | It is a type of testing where software modules are tested as a group and integrated logically. |
| Performance testing | It is to test how it is handling long running code. |
Here is the basic flow to use Apache Kafka as communication between microservices:
- Download and install Apache Kafka
- Start Zookeeper
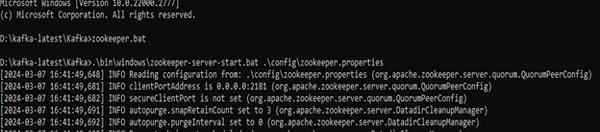
- Start Kafka Server

It runs on 9092 port by default with the Kafka server as a broker.
Now with the help of this address we can publish and subscribe the data.
To publish the publisher needs to provide topic name and the messages.
Multiple Subscribers can subscribe the topic which consists of messages.
Kafka Security
Let us do a deep dive into the key Kafka security concepts.
Data Protection via Encryption
Kafka supports SSL/TLS encryption for data communications between brokers and clients preventing unauthorized interception of data. The applications can be configured to use encryption when reading and writing to and from Kafka.
Authentication and Authorization
Authentication is the process of verifying user identity and authorization is the process of determining the actions which can be performed by the user.
Kafka supports the below protocols for authentication. It is important to choose the right authentication mechanism depending on the specific security requirements and level of trust needed.
SSL/TLS (Secure Socket Layer and Transport Layer Security): This can be implemented in Kafka cluster by using valid certificates. The client presents the certificate which is validated by the broker. By enabling this we can ensure the data communications are always secure.
Sample Broker configuration(server.properties)
Listeners=
Ssl.keystore.location=
Ssl.keystore.password=
Ssl.key.password=
Ssl.truststore.location=
Ssl.truststore.password=
Sample Client Configuration (client.properties)
Security.protocol=SSL
Ssl.truststore.location=
Ssl.truststore.password=
SASL (Simple Authentication and Security Layer): Allows clients to authenticate using different protocols like PLAIN, SCRAM or GSSAPI. This can be implemented by setting the required properties like security protocol, SASL mechanism, sasl jaas configuration etc. in the properties files.
Kafka allows the following mechanisms for authorization of user.
ACL - Access control lists allow access based on user groups or permissions. The level can set at Kafka cluster or topic or even at a transaction level allowing much flexibility.
RBAC – Role based access control allows pre-defined roles to be set to user or groups. It is better to choose RBAC mechanism if the user base is huge because of its scalable approach.
Integration with external systems for authorization: Existing authentication and authorization systems like LDAP or AD can also be integrated to ensure smooth implementation of access control.
Monitoring and Auditing
Kafka security concepts does not stop with implementing encryption and necessary authentication and authorization mechanisms. It needs continuous monitoring to detect any suspicious activities and respond to the same.
Som basic metrics which can be considered for monitoring includes Consumer lag, broker utilization, topic related metrics like number of messages produced/consumed etc. Advanced level metrics could monitor performance, network parameters. These metric values can be fed to external tools like Prometheus, Grafana etc. for creating meaningful visualizations.
Implementing Kafka Security and monitoring best practices is important for maintaining the confidentiality, and availability of a Kafka cluster.
- Ensure that Kafka cluster configuration is secure by setting strong passwords, disabling unnecessary features and protocols, and keeping up with software updates and patches to address security vulnerabilities.
- Implement monitoring and auditing mechanisms to detect and respond to security incidents. Monitoring logs can help to find any unauthorized accessing.
- Kafka Security best practices include enabling authentication and authorization, implementing encryption, securing cluster configuration, monitoring and auditing, network segmentation, regular training, and staying updated with security measures.
- Perform regular capacity planning by understanding the workload requirements, cluster sizing, proper resource allocation, metrics. Capacity planning should be performed regularly to ensure Kafka handling message volumes changes and other performance related issues.
- Reviewing metrics regularly to ensure that the Kafka is meeting the requirements. We can create the dashboards to check the Kafka clusters performance.
- Monitoring Kafka logs as it can quickly detect any errors and warnings or any root cause. Logs can help you to resolve problems such as delayed message processing, high message drop rate.
Kafka Performance
Kafka is increasingly being used across various applications including data streaming applications where vast amounts of data are being processed, and it becomes essential to ensure optimal performance. The 2 key metrics for Kafka performance are latency and throughput. Ideal situation is to have balance between minimal latency and maximum throughput.
Latency defines the time gap between a producer producing a message and consumer consuming the message. Minimal latency should be ensured in real time applications to minimize the impact of consequences.
Throughput measures the number of messages produced in a particular period. High throughput needs to be ensured to process vast data in minimal time.
Testing and Benchmarking
Test Kafka and identify the performance bottlenecks. Standard benchmark values have been created Kafka which can be used to validate the performance. Some of the common benchmark values include.
- Number of producers
- Number of consumers
- Number of topics
- Number of partitions
- Throughput
- Message size
Strategies for optimizing Kafka performance
- Optimize the infra and network configurations.
- Use compression mechanisms.
- Tune the number of partitions.
- Use caching mechanisms wherever applicable.
- Adjust the Kafka metrics dynamically depending on the situation.
Conclusion
Kafka is quickly becoming a popular choice for messaging in microservice architectures. Its distributed design and scalability make it well-suited for applications with many moving parts. Kafka can help you build more reliable and scalable applications. It can be an invaluable tool in your microservices.
References
Throughout the preparation of this whitepaper, information and insights were drawn from a range of reputable sources, including research papers, articles, and resources. Some of the key references that informed the content of this whitepaper include:
These references provided the foundation upon which the discussions, insights, and recommendations in this whitepaper were based.






Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!