Artificial Intelligence




Self-Healing Systems using AI based Auto-Remediation Strategies
Modern Enterprise IT architecture incorporates Cloud native applications, microservices, API based integration, all operating across cloud and on-premise environments. These systems face challenges in scalability, security, performance and redundancy, resulting in complex operations that demand automation beyond traditional rule based methods. Self-healing denotes the system capability to detect, diagnose and resolve incidents autonomously. The feasibility of this approach was previously limited in scope, because of the inherent limitations with rule based approaches. The recent advances in AI and ML present opportunities to significantly improve capabilities in self-healing architectures. The paper attempts AI driven strategies such as intelligent service restarts, automated scaling, failure rollbacks, traffic routing and security actions, while addressing challenges such as false positives. By adopting these approaches, enterprises can enhance system reliability, streamline operations and move towards fully autonomous IT systems.
Insights
- Implementation of self-healing architectures using AI and ML
- Broaden the scope for application resilience using novel AI patterns such as intelligent agents
Introduction
Modern Enterprise IT architectures are expected to be operational and reliable under adverse conditions. Their importance lies in minimizing downtime, maintaining business continuity and safeguarding data integrity. Enterprise Architects are expected to design systems that are versatile, scale in either direction, survive failures, easy to troubleshoot and configure, and must have only optimal costs. As systems grow more complex in terms of components, connectivity and user load, the problem becomes complicated. Current approaches to solve the problem are largely based on rule-based logic, which faces challenges due to the large number of variables in the mix. Emerging technologies such as AI driven anomaly detection, self-healing systems and edge computing are reshaping resilient system implementations, promising greater adaptability in the face of challenges.
Definition and Characteristics of self-healing systems
A self-healing system is one that can autonomously detect anomalies, diagnose root causes and execute corrective actions without active human intervention. The concept of self-healing is inspired from nature, where biological organisms can detect damage and can initiate organic recovery to restore normal functions. In the context of modern-day digital applications, self-healing systems can minimize downtime, improve resilience from failures and reduce the operational overhead of maintenance and incident responses.
Key Characteristics
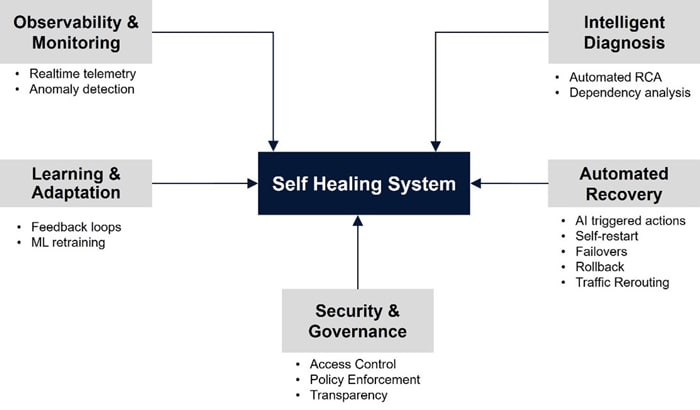
| Autonomous Monitoring | Constant and intelligent observation of system health metrics to detect anomalies in real-time |
| Independent fault detection | Analyze the collected data to recognize deviations from expected behavior |
| Diagnose root causes | Based on the analysis, identify the root cause |
| Identify and perform corrective action | Pick out the most suitable corrective action for the root cause and execute it |
| Continuous learning | Refine the knowledge base constantly so that the system gets better over time at recovering from faults |
| System transparency | Clear visibility into how the system detected the errors, performed diagnosis and executed the corrective actions |
| Adaptability | Capable of reacting to potentially undesirable changes in operating environment |
Key Success Factors
Agility and evolution: Any proposed solution should not be based on rigid predefined logic. Instead, it should be capable of observation and evaluation, and dynamic evolution to adjust to changing environments.
Automated self-healing capability: For mission critical applications, each second of downtime may translate to financial loss or loss of brand equity. Manual intervention is to be eliminated using health checks, auto restarts, autoscaling, auto-replacement of unhealthy instances etc.
Robust failure detection: State-of-the-art Observability capabilities are needed to prevent getting blindsided by failures. Structured logging, metrics, distributed tracing can help here. Real-time alerting capabilities are a must-need.
Idempotency capability: This refers to the capability of the design to be able to accommodate an operation being performed multiple times. There are no unintended effects such as duplicate entries or inconsistency in databases. This allows applications to build safe retry mechanisms which can guard against transient failures, network issues, application crashes etc.
Configurable and modular architecture: This helps in easy isolation of failures and then facilitates simplified recovery. Microservices and event driven architecture enable loose coupling. Feature flags help enable or disable features at runtime without having to perform risky measures such as new code deployment.
Simplicity of implementation: The finer details of the AI/ML implementation should be abstracted out and hidden from the view of the end users. The tools should be easily plugged into existing software deployments. Tools like containers, sidecars, service meshes etc. fit well into serving this purpose.
Current state and challenges
Currently there are well established architectural guidelines for implementing application resiliency and self-healing. These include failure detection through observability, graceful degradation, automated recovery using retries and circuit breakers, loose coupling etc. All the widely adopted programming languages and frameworks support the implementation of these patterns as well. However, challenges remain as follows.
- Resiliency implementation often implies the requirement of distributed systems architecture, which comes with inherent complexities. Similarly, there is added technical complexity when implementing circuit breakers, retries etc.
- State management: Approaches like container restarts assume stateless architecture. Maintaining state across restarts is often a challenge.
- Added latency is often an unwanted side effect of resiliency implementations. (E.g. Retries).
- Validating all failure scenarios is extremely difficult, despite the advent of Chaos Engineering.
Traditional approach to building resiliency
Traditionally, there is a lot of focus on finding vulnerable code that can cause memory leaks, CPU spikes, network vulnerabilities etc. There are many commercial tools that provide code scanning functionality specifically for different languages, like Java, C# etc. Similarly, monitoring tools look for specific patterns on running software and trigger alerts when thresholds on CPU, memory or disk are breached.
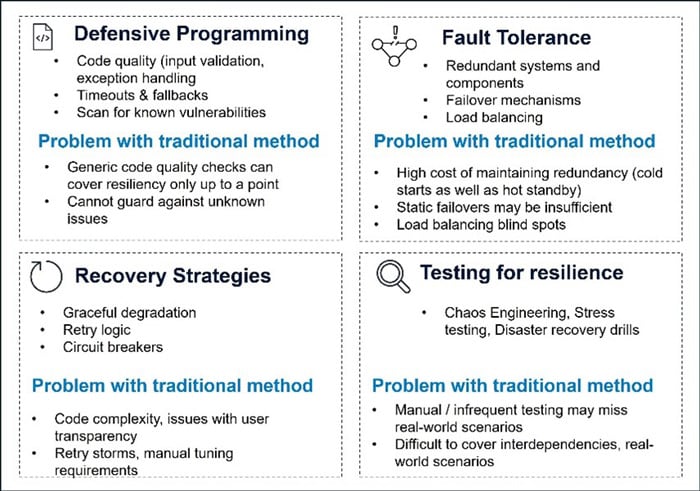
All the above approaches are reactive rather than proactive. They rely on a) existing literature and best practices to roll out a ‘best-guess’ candidate for the initial release, and b) iteratively try to refine it by reacting to issues that arise and rolling out fixes. However, this approach is human-dependent for resolution. Also, in complex systems, the cycle of issue detection – RCA – fix can take long, and thus the recovery time will be slow. The problem is amplified in modern dynamic cloud-native environments due to the complexity curve being higher.
A framework for AI based resilience
To systematically build resilience in software systems using AI, organizations need a structured, end-to-end implementation framework. This framework should bridge the gap between raw observability data, intelligent decision-making, and automated recovery. It should implement a closed loop process by which learnings and feedback are absorbed to continually refine the process. Below is a layered model that defines the core components and flow of AI-based resilience implementation.
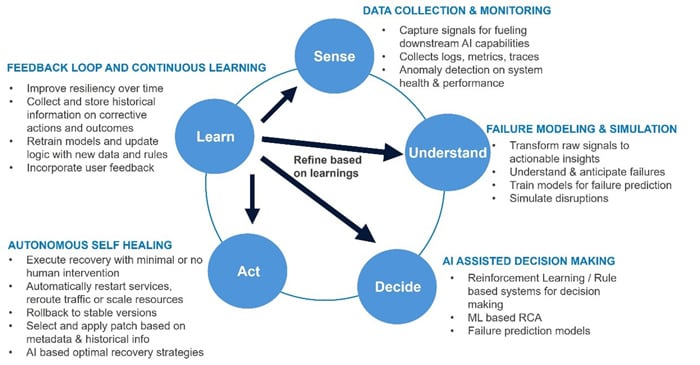
The outcomes of each cycle feed back into the system, enabling it to refine its detection, diagnosis, and response mechanisms over time, thus creating a self-improving loop of resilience.
Observation layer (Sense)
This foundational layer is responsible for capturing signals from across the system. The key action here is about enabling continuous monitoring to capture the relevant information, which may be present in application logs, metrics or traces. The data captured here will be the basis upon which all the downstream AI capabilities will depend on. The key data sources can be the following.
| Category | Examples |
|---|---|
| Metrics | CPU and memory utilization, Network and disk I/O, error rates, service latency |
| Traces | Application logs, system logs, audit logs (mostly semi / unstructured data) |
| Logs | Distributed tracing (e.g. OpenTelemetry) |
| Events | Deployment events, configuration changes, operator interventions |
| User Interactions | Clickstream data, usage patterns, user feedback |
| External dependencies | API response times, 3rd party service status, external events (e.g. major vulnerabilities, weather data near datacenters) |
| Business signals | Transaction failures, domain specific events (abandoned shopping carts on shopping websites, very large look-to-book ratios in a travel app etc.) |
Scope for applying AI / ML
- Anomaly detection: There is scope to detect outliers from metrics or logs.
- Feature engineering: Raw logs/metrics can be enriched with metadata (service name, correlation IDs, tags).
- Noise reduction: False positives in alerts can be eliminated by correlating with related metrics or known patterns. Data deduplication can be performed so that the same incident is not flagged multiple times.
- Dynamic thresholding: Avoids alert fatigue by detecting meaningful deviations rather than hard-coded spikes.
Enabling technology
| Monitoring tools | Prometheus, Grafana, AppDynamics, Datadog, New Relic, CloudWatch |
| Tracing systems | OpenTelemetry, Jaeger, Zipkin |
| Logging pipelines | ELK stack (Elasticsearch, Logstash, Kibana) |
| Event brokers | Kafka, Amazon Kinesis, Google Pub/Sub |
Risk Mitigation Strategies
| Challenges | Solution(s) |
|---|---|
| Data spikes that can cause capacity overloading. There is a need to handle massive, diverse and fast moving data sets. | Use patterns like autoscaling, message queue based load levelling, competing consumers, throttling etc. |
| Sensitive data can come through, which if leaked can lead to eventualities like loss of brand value, financial loss due to business impact etc. | The ingestion pipeline’s initial stage can tag sensitive fields for masking or encryption by the downstream stage. Ensure that data is encrypted while in motion and rest. |
| Inaccuracy in data ingestion | High Cardinality support: Ensure that observability tools can tackle high cardinality data and label them. Use identifiers to correlate data in different swim lanes like traces and logs. Adopt consistent naming conventions and structured logging |
| High costs due to large / varying data loads | Choose what to store: reach the optimum balance between data necessities and (storage + processing) costs |
Real-world example
A retail shopping platform is implemented as microservices on a public cloud Kubernetes cluster, spanning hundreds of pods. An AI based anomaly detection service runs a supervised model on service latency, to flag unusual spikes before SLA breaches are triggered. Relevant application log information is captured and enriched with Kubernetes pod metadata. Subsequent analysis infers that the problem was induced by a recent release.
Interpretation layer (Understand)
The Interpretation Layer translates raw signals from the Observation Layer into insights, diagnoses, and meaningful context. It bridges data collection and action by applying AI models, inference engines, and domain knowledge to detect why something is happening, how bad it is, and what it affects. This layer helps prioritize issues, reduce mean time to detect (MTTD), and prepare for automated or guided remediation.
Scope for applying AI / ML
| Capability | AI technique | Applicable Technologies |
|---|---|---|
| Anomaly correlation | Decision trees, random forests, Graph based algorithms, SVM, time series analysis, clustering (K-Means, DBScan) | Scikit-learn, XGBoost, Neo4J, ARIMA, SciPy |
| Root Cause Analysis & Identification | Supervised learning from ticket history, knowledge graphs, service dependency graphs to trace fault propagation | TensorFlow / PyTorch, Neo4J, Spark MLib |
| Assess Blast Radius / Impact assessment | Causal modeling using Graph data, KNN, similarity searches | Scikit-learn, FAISS / Milvus / Weaviate |
| Issue summarization | BERT derivatives, Transformer models | Hugging Face Transformers, TensorFlow / Keras |
| Issue triage | Deduplication using cosine similarity, classifiers | Sentence Transformers, TF-IDF using Scikit-Learn |
Risk Mitigation Strategies
| Challenges | Solution(s) |
|---|---|
| Incomplete or noisy data | Employ strategies like deletion (drop excessive missing values) and imputation (mean/median/mode, KNN similarity values, regression). Use domain specific rules to fill data gaps. Smoothing, filtering and transformation strategies for handling noisy data. |
| Multi-tenancy Noise: Shared systems might make mistakes in attribution issues if the context is missing | Deduce and add context identifiers, ensure separation and presence of safe defaults |
| False Positives in Causality: Correlation does not imply causation — model tuning is critical. | Improve feature engineering to add/refine features that distinguish true and false positives. Ensemble methods (multiple model combinations) can reduce variance |
| Model Drift: As systems evolve, historical patterns may no longer be valid. | Ensure model retraining on a scheduled basis. In cases of high accuracy, retrain as needed, or look for a better model. Employ human-in-the-loop as needed. |
| Anomaly detection and root cause analysis are highly correlated with the technology and domain context. Generic solutions may be ineffectual, calling for domain & technology specific knowledge in building or fine-tuning solutions. AI needs to be able to distinguish between benign and critical anomalies without additional logic | Domain driven anomaly detection ( via heuristics, thresholds and known patterns), feedback integration. Implement bias mitigation and outlier detection |
Real-world example
In a large-scale payment platform, an AI-based RCA engine detects increased latency in user checkout flow. It correlates this with a spike in log entries containing timeout in a downstream inventory service. By consulting the incident knowledge base, the system identifies a known pattern caused by a misconfigured DB connection pool during high concurrency. A resolution summary is proposed, reducing MTTR by 70%.
There are many use cases for implementing AI based problem understanding and RCA, as below:
- Detect recurring application issues such as memory leaks
- Detection of well-known security breach patterns
- Determine microservice performance issues from latency data or CPU usage
- Intrusion detection from IP data or packet analysis
Decision layer (Decide)
In the Decision layer, AI models are equipped with information from the previous layer to decide on the most appropriate course of action. The insights are operationalized by choosing from multiple courses of action (as detailed in the next section). Accurate decision making is critical to reducing the Mean Time to Resolution (MTTR) and ensuring the overall success of the automated resiliency mechanism.
Scope for applying AI / ML
AI/ML methods in this layer facilitate decision making under uncertainty. They can evaluate multiple course of actions and balance trade-offs.
| Capability | AI technique | Applicable Technologies |
|---|---|---|
| Handling ambiguity and uncertainty | Bayesian networks, Markov processes, ensemble methods | Pgmpy, pymc, scikit-learn(Ensemble) |
| Modeling complex dependencies (modern software platforms have multiple levels. Microservices are a good example) | Deep learning, Knowledge graphs | Pytorch, Neo4j |
| Playbook recommendation | Analyze historical data to arrive at known remediation steps | Elasticsearch + KNN, FAISS and Sentence Transformers |
Risk Mitigation Strategies
| Challenges | Solution(s) |
|---|---|
|
Setup a well thought out playbook that covers the entire spectrum of scenarios and choices to be made in the decision making process. Incorporate business priorities like SLAs, compliance constraints, customer impact in the decision logic. |
| Models may face hitherto unseen scenarios. Possibility of hallucinations leading to bad decisions. |
|
| Ethical and Safety Constraints: In production systems, risky automated decisions can lead to downtime or data loss. |
|
| Aligning automated decision making with enterprise policy and compliance |
|
Real-world example
Netflix has a huge multitude of batch type computational processes which are necessary for the operation of their big data platform. Failures, even at a tiny fraction, may trigger unacceptable problems. Netflix has implemented the following to handle this.
- A rule-based classifier which classifies job errors and generates input for schedulers to decide if jobs are to be retried. Engineers can use the same data to diagnose and remediate the failure.
- An auto-remediation feature which integrates the rule-based classifier with an ML service. Based on the classification, the ML service predicts the retry success probability and retry cost, and selects the best candidate configuration, which is fed to a configuration pipeline to automatically apply the recommendations.
On productionizing the above, Netflix reports that 56% of all memory configuration errors are successfully auto remediated without human intervention. Costs are reduced by 50% due to the ability to make new configurations and disabling unnecessary retries. They also see further downstream improvement scope through model tuning.
Action layer (Act)
In this stage, responses derived from earlier stages are used to pick one (or several) actionable responses that can restore (or maintain) system stability. Typical responses would be actions like scaling up / down, restarting services, applying configuration changes, performing deployment actions, or even rollback. The objective of this stage is to execute these actions with minimal human intervention if any, while ensuring operational stability. All actions taken are thoroughly logged for later examinations.
The importance of this stage lies in the fact that swift actions can prevent operational outages, cascading failures as well as preventing breach of Service Level Agreements.
Software resiliency action implementation
Resiliency in systems can be achieved by designing architectures that anticipate, detect, and recover from failures autonomously. There are well known best practices and design patterns for remediation actions as depicted below.
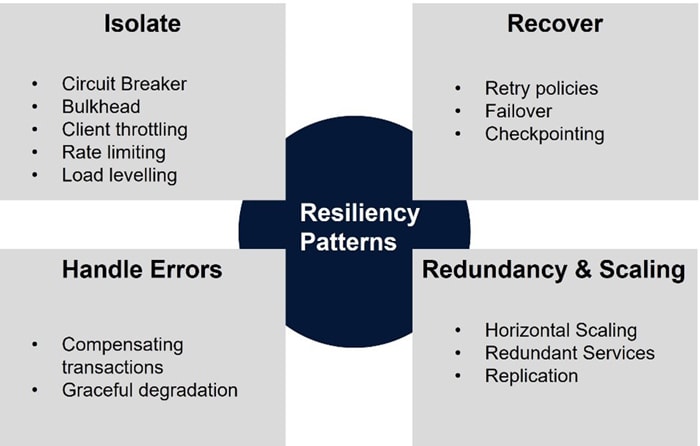
A set of automatable, common remediation techniques are listed below.
| Action | Example |
|---|---|
| Restart | Re-initialize a unit of computation, which can be a machine, VM, application service |
| Scale | Increase / decrease units of computation. (add or remove VMs, pods etc.) |
| Rollback | Revert to previous version |
| Patch | Auto deploy hotfix from repository |
| Isolate | Remove traffic from coming to a VM, database etc. |
| Reroute | Change load balancer or web traffic routing rules. An example could be failover to a secondary region |
| Notify | Inform key human stakeholders about potential issues |
| Seeking approval from human | Get approval from key human stakeholder(s) before performing a corrective action |
However, the true value of a self-healing system is realized when it becomes capable of taking actions – based on anomaly detection and root cause analysis, without any human intervention. Some strategies for autonomous remediation are described as follows:
1. Remediation playbook preparation and selection
A logical approach would be the preparation of several playbooks, each implementing a particular course of action, as response or fix to one possible problem among many. The choice of a playbook can depend on several factors, and a vector database is a good fit here. The output from the RCA phase can be searched using similarity scoring using cosine similarities on embeddings, to suggest known fixes. Availability of good historical data on issues and their fixes is of critical importance here. The following steps can be followed:
- Examine the current Operating Procedure / Manual for comprehensive coverage of all possible scenarios and their remediating actions.
- Identify the actions and see how they can be enriched to mitigate risks. Ensure that for every action, there is remediation, notification channels (and approval workflows where needed)
- Clearly define the criteria for triggering the actions, without ambiguity
- Prepare the mechanism whereby the playbooks can be triggered by AI. As an example, the playbook implementation may be a Terraform script which can be executed via MCP by an agent.
2. Orchestration of actions
Remediation is usually a set of steps, executed within guardrails and following fixed guidelines. AI agents are a natural fit in this scenario. Agents can do checks like pre and post validation, dependency resolution, sending notifications etc. Agents can act autonomously as well as seek human intervention or approval. They can act alone or collaborate as multi-agent architectures.
3. Policy driven automation
A policy driven framework can be implemented to ensure that corrective actions do not run amok. The policy can define which actions (out of a superset) are safe for autonomous execution. For e.g., scale up / scale down Kubernetes pods is fine, but adding a node is not permitted. Other possibilities include defining environmentally specific rules (e.g. stage vs prod), time of day (e.g. permit automated resilience during off-peak hours only) etc. Another aspect of the policy implementation is auditing the actions. The audit log must contain information on the exact action, date and time, rationale for taking the action (depending on the AI model), and the identity credentials that are used to execute the action.
Scope for applying AI / ML
| Capability | AI technique | Applicable Technologies |
|---|---|---|
| Prioritization of actions for addressing concurrent issues (how to handle multiple ongoing issues in a system) | Supervised learning: classification model for mapping incidents to remediation playbooks, decision trees for rapid mapping of problem to solutions, knowledge graphs for mapping complex dependencies | Orchestration engines – Apache Airflow with AI Plugins, |
| Intelligent orchestration of workflows | Reinforcement learning to learn optimal workflows over time | Cloud self-healing tools – AWS Systems Manager automation, Azure Automanage, Kubernetes operators, DevOps platforms like PagerDuty, OpsGenie |
| Remediation Workflows using Agents | Agents can scan for specific (and commonly occurring) problems. E.g. Monitoring system detects memory usage spikes, alert is raised, RCA agent determines memory leak, notifies SRE agent that performs a restart | Custom agent implementations |
| Human-in-the-loop integration | Agentic implementation for:
|
Custom agent implementations |
| Put tools in the hands of an AI system to take appropriate actions | Agentic AI implementation, uses MCP to pick the necessary tools to take corrective action. | Custom agent implementations using LangGraph, FastMCP etc. |
Risk Mitigation Strategies
| Challenges | Solution(s) |
|---|---|
| Wrong actions: AI took a wrong turn and made a catastrophic mistake. | Fail-safe mechanisms: Mitigation measure through manual override or fallback if AI decision goes wrong. Plot all scenarios and have playbooks ready for handling failures. When an action fails, there must be strategy in place for rollback and incident management. Blue-Green rollouts can help by testing actions for a fraction of the workload before rolling out to the entire audience |
| Latency: The action execution must be completed within strict time windows to ensure effective intervention | Ensure implementation of timeouts and proper error handling in the Actions. Effectively use logs and alerts for corrective intervention as needed. |
| Change management: As with classic DevOps implementation, letting AI take over is a cultural shift, and traditional Operations teams will be reluctant to cede control |
|
| Interdependency issues: In the case of large distributed systems, there is a high likelihood that change in one part may trigger unintended consequences elsewhere | Map service and data dependencies, use graph based models for impact analysis. Compare with historical decisions to predict the outcome |
| Security concerns: AI based auto-remediation systems must be tightly controlled and constantly analyzed to guard against potential intrusion and abuse. Privilege escalation is a high-risk scenario. | Implement Audit trails: Every AI triggered action should have an audit log with detailed explanation for future audit purposes. The log should contain enough information to attribute why AI took the particular action. |
Real-world example
Scenario: Degraded application performance of microservices running on a Kubernetes cluster
AI Response Flow:
- Detect: Increased API / web latencies breach SLA levels and trigger alerts
- Diagnose: All related data concerning the incident is collated. This includes application logs, metrics on CPU, memory, network utilization etc.
- Input data is standardized and fed to a deep learning model.
- Summarized description of the data is prepared using an LLM. A similarity search is done on a vector database to retrieve similar past incidents
- Both methods point to high CPU utilization caused by well-known code issues from the recent prod deployment
- Notification sent to human stakeholders with request for approval of auto-remediation
- Remediate:
- AI agent retrieves suitable playbook for remediation by searching vector database for proximity with earlier similar and successful corrective actions
- AI agent prepares a list of steps that will be executed. In this case, this is about rolling back to the previous release and recycling the pods
- Playbook is executed and notification containing the detailed steps are sent to human stakeholders
- Verify: AI agent monitors performance metrics to see if they are stable
- Feedback: The action is marked as success, and the remediation pattern is reinforced.
Some additional real-world examples for AI driven resiliency actions are as follows:
- Cloud and Data Center Operations: Automated resolution of server crashes, resource bottlenecks, and network failures.
- Enterprise Applications: Self-healing microservices architecture to ensure high availability.
- Cybersecurity: AI-driven threat detection and automatic remediation of security vulnerabilities.
- DevOps Pipelines: Continuous monitoring and automated rollback mechanisms in CI/CD environments
Feedback incorporation layer (Learn)
The Learning stage is concerned with continuous improvement of the resiliency system. It captures information about the state of the system after the remedial action has been performed and compares it with the expected behavior. This information is used to refine the decision-making process. This stage is essential in building decision making systems that learn and adapt over time.
Corrections are applicable to any of the preceding four phases. Some possibilities for applying corrections are as shown below:
| Sense – Data collection |
|
| Understand – Insight generation |
|
| Decide – Decision Making |
|
| Act – Execution & Orchestration |
|
Scope for applying AI / ML
| Capability | AI technique | Applicable Technologies |
|---|---|---|
| Automated feedback ingestion and model tuning | Retraining pipeline implementation | Apache Airflow |
| Model drift detection (data drift, model drift), performance degradation detection | Statistical tests like Kolmogorov-Smirnov, Chi-Square | Scikit-learn, Mlflow.org, AWS Sagemaker Clarify, Vertex AI Model Monitoring, Haystack, |
Risk Mitigation Strategies
| Challenges | Solution(s) |
|---|---|
| Outcomes may not always be ‘success’ or ‘failure’. In case of ambiguous results, data may not be suitable for retraining. | Check the data quality through visualizations and presence of outliers. Ensure that there is no overfitting. Ensure that false positives and false negatives are eliminated before using the data for retraining |
| Attribution of actions: In complex environments, it may be difficult to accurately gauge the impact of a remedial action. | Ensure that a comprehensive troubleshooting framework is in place. Use traces and observability tools to detect and isolate the outage. Dependency mapping tools (e.g. Kiali) can help in visualization. Log aggregation facilitates centralized log analysis. |
| Cost associated with retraining (in terms of data collection overhead as well as retraining computation) may lead teams to reduce the emphasis on this stage. | Optimize data usage by sampling, cleaning, dimensionality reduction etc. Investigate feasibility of model optimization (smaller models, transfer learning, quantization) and efficient experimentation (hyperparameter tuning, use of tools like MLFlow etc.) |
| Bugs, performance issues and potential security issues associated with model changes |
|
Real-world example
Early versions of facial recognition systems failed at recognizing people with darker skin tones. The obvious reason being that the training data exclusively consisted of one type of skin tone. After well publicized failures in production, extensive model retraining with heterogeneous data helped solve the problem.
Another example is from a case when a model was trained to identify roads and waterways in the United States from satellite imagery. The data collection stage forgot to consider the difference in seasonality. The landscape looks dramatically different across seasons, and all the training data was taken during springtime. Without retraining with data across seasons, the model will find it difficult to recognize features from different times of the year.
Future directions
Some interesting possibilities which self-healing IT systems can evolve into are as follows:
- Adaptive Immune systems: The premise here is that the model training, based approach has limitations in handling the complete spectrum of problems that can happen at runtime, as technology evolves all the time. Artificial Immune Systems (AIS) are a machine learning paradigm inspired by the principles of biological immune systems - https://arxiv.org/pdf/2101.02534
- Edge Computing Integration: AI-powered self-healing at the edge to enhance IoT resilience. Lightweight models are used for on-device diagnosis and remediation. Multiple agents can collaborate to correct the system, using swarm intelligence. An example would be a drone experiencing failure informing neighbors. The drone fleet performs autonomous recalibration to take over the workload of the failed one.
- Cyber security integration: There are multiple possibilities in this area, including ai-powered intrusion detection with autonomous mitigation, self-healing identity and access management, ai driven policy enforcement, dynamic honeypots and deception systems etc.
- Explainable AI in self-healing contexts: AI based anomaly detection, RCA and remediation will all include comprehensive explanation on how the model came to conclusions. The AI can also check with conformation to organizational policy in performing corrective actions and add the information to audit logs.
- Reinforcement learning for autonomous actions: AI agents employing RL is a good fit as they improve over time. The AI can try multiple approaches, measure effectiveness, determine the actions with highest success rates and avoid potentially risky or damaging actions.
Conclusion
Self-healing IT systems represent the next step in the evolution of IT operations. Businesses can transition from reactive problem solving to proactive and autonomous system management. Highly resilient IT architectures can be built by incorporating AI and ML based techniques such as anomaly detection, fault prediction and autonomous remediation. The prospect of improved business continuity, operational efficiencies and overall system performance imply that this is an unavoidable consideration for any IT leader. As AI technologies continue to advance, self-healing systems will become more sophisticated, driving innovation in IT operations and ensuring seamless digital experiences.
References
Throughout the preparation of this whitepaper, information and insights were drawn from a range of reputable sources, including research papers, articles, and resources. Some of the key references that informed the content of this whitepaper include:
- “Artificial Intelligence for enhancing resilience” – Nitin Liladhar Rane, Saurabh P. Chaudhary, Jayesh
- “Self-Healing Infrastructure” – Red Hat Architecture center, November 2023
- “Design for Self-Healing” – Microsoft blog, July 2024
- “Detecting data drift using Amazon SageMaker” – AWS Architecture blog
- “Introduction to Vertex AI model monitoring”, GCP documentation
- “Why, When and How to Retrain Machine Learning Models”, striveworks.com
- Dohare, S., Hernandez-Garcia, J.F., Lan, Q. et al. Loss of plasticity in deep continual learning. Nature 632, 768–774 (2024).
- “Evolving from Rule-based Classifier: Machine Learning Powered Auto Remediation in Netflix Data Platform” – Netflix technology blog, March 2024
- M. Baqar, R. Khanda, and S. Naqvi. 2025. Self-healing software systems: Lessons from nature, powered by AI. arXiv preprint arXiv:2504.20093
- Shivam Gupta, Sachin Modgil, Regis Meissonier, Yogesh Dwivedi. Artificial Intelligence and Information System Resilience to Cope With Supply Chain Disruption. IEEE Transactions on Engineering Management, 2021, pp.1-11. ff10.1109/TEM.2021.3116770ff. ffhalshs-03546175f






Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!