
Research & Applied Innovation

Most enterprises already have plenty of information. The real challenge is finding the right information when it is needed.
Organizations accumulate proprietary knowledge across technical documentation, knowledge bases, standard operating procedures, issue-resolution repositories, sales materials, and employee-authored content. The problem is not that this knowledge doesn't exist — it is that users often cannot find the right answer quickly, consistently, or in context.
This challenge sharpens as enterprises adopt retrieval-augmented generation (RAG) systems. A fine-tuned large language model (LLM) can generate fluent responses, but fluency does not guarantee factual grounding in current enterprise content. RAG addresses this by retrieving relevant content before response generation, grounding answers in retrieved enterprise information. Most RAG deployments, however, still depend on general-purpose embedding models that were not trained on enterprise terminology, internal product names, abbreviations, or work-specific language patterns [2].
Why it matters: General-purpose embeddings understand language patterns. Enterprise-adapted embeddings understand enterprise context. This distinction directly affects retrieval quality.
Infosys addressed this problem through EnterpriseEM, an enterprise embedding approach designed to improve semantic search across internal knowledge sources. Rather than building a model from scratch, EnterpriseEM fine-tunes strong pretrained retrieval models against enterprise data, language, and usage patterns. The core premise — that retrieval quality improves when the model understands the enterprise it serves — is straightforward. The work demonstrates how to put that premise into practice (Figure 1).
Figure 1. EnterpriseEM end-to-end architecture

Note: The pipeline transforms raw enterprise content into semantically aligned retrieval results through annotation, synthetic generation, fine-tuning, and reranking stages.
Source: Infosys Topaz Fabric Studio
Retrieval quality is often decided before model training begins. Noisy, duplicated, or poorly segmented source content limits what any model can accomplish downstream. Infosys built the EnterpriseEM dataset from a wide range of internal sources: technical course content, knowledge base articles, standard operating procedures, query-and-resolution repositories, sales data, and employee blogs. Text was extracted from PDFs, Word documents, Excel files, PowerPoint presentations, and web pages. Audio, video, and image content were deferred to a later phase. Standard parsing approaches were applied to both structured and unstructured formats, converting raw enterprise content into a form suitable for reliable retrieval and evaluation.
The preprocessing pipeline had one purpose: make enterprise content safe, clean, and retrieval-ready. Sensitive information was identified and masked before training or evaluation, so that internal data could be reused while preserving its value. Text was cleaned to remove markup, scripts, and extraction noise; difficult cases — tables, lists, and non-English passages — were reviewed manually where automated handling was insufficient.
Documents were then converted into retrieval-ready units. Structured data was flattened into readable text, contextually independent paragraphs were separated, and content was split into chunks using recursive text splitting. The final dataset contained approximately 17 million tokens across 65,200 chunks, with most falling between 300–500 tokens. Figure 2 summarizes the full preprocessing pipeline and the objective of each stage.
Figure 2. Preprocessing steps applied to enterprise content before training and evaluation
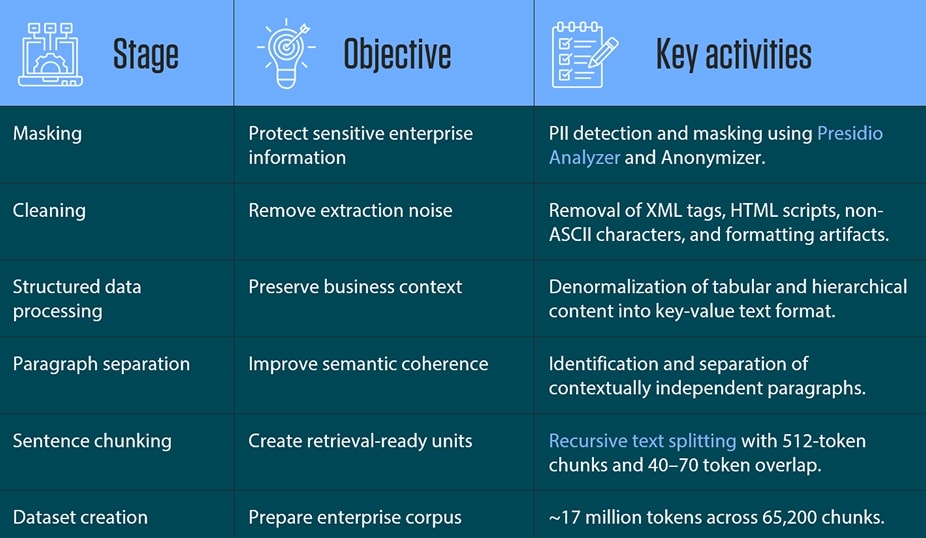
Note: Synthetic question generation follows as a separate pipeline stage and is covered in Section 4.
Source: Infosys Topaz Fabric Studio
Enterprise users rarely phrase questions the same way. Some queries are direct and factual. Others are scenario-based, expressed in team-specific language, or structurally ambiguous. A retrieval model that has seen only one style of question will perform inconsistently across a diverse user population.
To improve coverage, synthetic questions were generated from the cleaned and chunked corpus using Mixtral-8x7B-Instruct-v0.1. Generation spanned seven query styles: factual, clarification, interpretation, consequence-related, extractive, subjective, and reasoning-based. Multiple generation rounds were run, with weaker outputs removed through structured review. The final set comprised approximately 300,000 synthetic questions generated from enterprise content.
This gave EnterpriseEM exposure not only to what enterprise content says, but to the range of ways employees are likely to ask for it, a meaningful distinction for a model serving a diverse user population.
Generic named-entity recognition is insufficient for enterprise retrieval. Internal product names, platform names, client references, business terms, and organization-specific vocabulary carry meaning that general-purpose models may not interpret correctly. Without an explicit signal about what these terms represent, a retrieval model treats them as ordinary text strings and misses the semantic distinctions that matter to the user.
Infosys created a custom entity layer using a curated dictionary of approximately 500 organization-wide entities and entity types. Automated pre-annotation was combined with structured manual refinement. The dataset was divided into batches of 50 chunks, each independently reviewed by three trained annotators. Annotators completed a specialized course developed with Infosys's Education, Training, and Assessment team. Only entities agreed upon by all three reviewers were retained.
Key insight: Treating internal products, platforms, business concepts, and organizational terminology as explicit entities improves enterprise retrieval quality. The model no longer guesses the meaning of internal terms — it learns them.
A concrete illustration: in a passage describing Infosys's collaboration with Tennis Australia, "Infosys Meridian" was identified as an enterprise platform during entity annotation. The annotated version generated questions that reflected the platform's role within the source content more explicitly than the non-annotated version. Annotation does not change the content — it makes the content's structure visible to the model. Figure 3 illustrates how entity annotation transforms unresolved text strings into semantically grounded retrieval results
Figure 3. Impact of entity annotation on retrieval
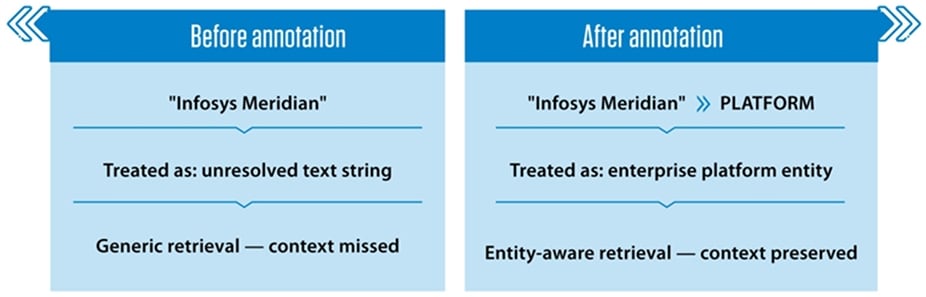
Note: Annotating internal platform names as explicit entity types enables context-aware retrieval, replacing generic text-string matching with semantically grounded results
Source: Infosys Topaz Fabric Studio

A retrieval system should be evaluated using queries and content that reflect its intended operating environment. Public benchmarks are valuable for comparing models across domains, but they cannot substitute for evaluation against enterprise-specific content and user queries.
To support this evaluation, Infosys manually curated a benchmark dataset of 2,500 question–chunk pairs derived from actual end-user queries and corresponding subject-matter-expert-provided answers. The benchmark was designed to reflect real-world enterprise search scenarios, with a representative distribution across enterprise content types.
The benchmark was cleaned to prevent overlap with training data and distributed proportionally across content types. The train-to-validation split was maintained at 95:5 for each content type, ensuring that evaluation reflected the diversity of content and query patterns in the dataset rather than any single content category.
Model selection balanced several criteria: semantic search relevance, benchmark performance, model size, embedding dimensions, and context length.
Three models were selected. e5-large-v2 served as a strong general-purpose dense retrieval model [3]. mxbai-rerank-large-v1 was chosen as a dedicated reranker [4]. ColBERTv2.0 was included for both retrieval and reranking experiments [5]. Its late-interaction architecture — which computes token-level similarity at query time rather than collapsing a document to a single vector — makes it effective in two distinct pipeline roles: standalone retrieval and reranking. Retaining both e5-large-v2 and ColBERTv2.0 allowed the evaluation to test whether late-interaction retrieval, dense-vector retrieval, and cross-encoder reranking each contributed differently to enterprise search quality.
To place the results in context, the evaluation included both open-source and commercial embedding models, including text-embedding-ada-002 and text-embedding-3-small. Comparing EnterpriseEM against these alternatives provided a broader view of retrieval performance across different embedding approaches [6].
Fine-tuning of e5-large-v2 and mxbai-rerank-large-v1 was performed using the SentenceTransformers library. ColBERTv2.0 fine-tuning used the vRAGatouille framework.
Multiple retrieval-training formats were evaluated, including query–positive pairs and variants incorporating hard-negative examples, identified using the GPL (Generative Pseudo Labeling) hard-negative mining technique [7]. The optimal format differed by model type.
For e5-large-v2, the query–positive pair format (without negatives) delivered the best retrieval performance, with MultipleNegativeRankingLoss proving the most effective training objective. For mxbai-rerank-large-v1, the query–positive–negative triplet format outperformed other configurations, training the reranker to explicitly distinguish relevant from irrelevant text for a given query.
All fine-tuning experiments were conducted on a single NVIDIA A100 80 GB GPU. Training durations remained practical for enterprise environments, taking approximately 8 hours for e5-large-v2, 12 hours for mxbai-rerank-large-v1, and 6 hours for ColBERTv2.0. These results demonstrate that meaningful retrieval improvements can be achieved without large-scale training infrastructure.
Rather than focusing solely on benchmark performance, the evaluation explored whether enterprise-specific fine-tuning delivers more relevant results for employees in their day-to-day work. Results were measured using Normalized Discounted Cumulative Gain (NDCG@3), Mean Average Precision (MAP@3), Precision@3, and Recall@3 — each computed at retrieval depth three, meaning only the top three returned results were evaluated. Figure 4 summarizes the fine-tuning workflow, model configurations, and compute profile used across experiments.
Figure 4. Fine-tuning workflow
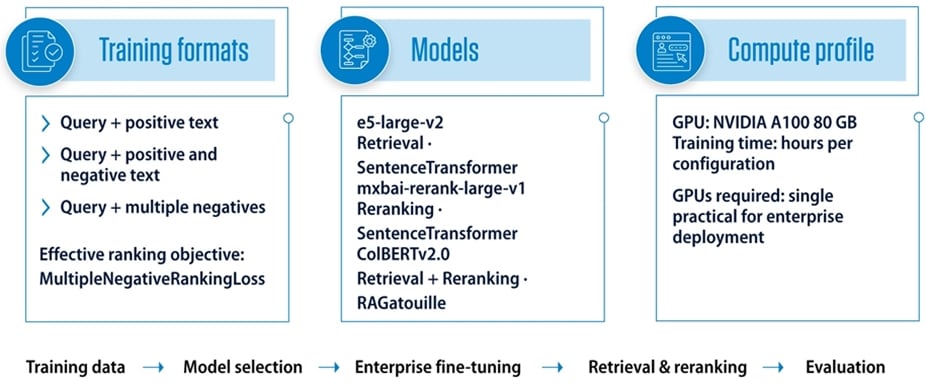
Note: Fine-tuning workflow used to adapt pretrained retrieval models to enterprise search requirements. All experiments ran on a single NVIDIA A100 80 GB GPU.
Source: Infosys Topaz Fabric Studio

Metrics were computed using the BEIR library, a benchmark framework for evaluating retrieval models across diverse tasks [8]. The evaluation used four top-result retrieval metrics, each measured at depth three — meaning only the top three returned results were evaluated:
The pattern across experiments was consistent. Pretrained models established a meaningful baseline. Fine-tuning improved performance across every configuration tested. Reranking generally added further value. The strongest result came from fine-tuned ColBERTv2.0 used as a standalone retrieval model, reaching NDCG@3 of 93.4%, MAP@3 of 92.4%, and Precision@3 of 96.2%. Figure 5 shows NDCG@3 performance across pretrained and fine-tuned configurations.
Recall@3 ranged from 28.2% to 32.1% across configurations, a figure best read alongside Precision@3 given the constrained @3 evaluation window.
Understanding the metrics: Recall@3 score of 32.1% does not indicate poor retrieval performance. Precision@3 asks: of the three results returned, how many are relevant? At 96.2%, nearly every result the model returns is correct. Recall@3 asks: of all relevant passages in the corpus, how many appear within the top three results? Because evaluation is performed at depth three, Recall@3 measures coverage within a deliberately constrained window. It should be interpreted alongside Precision@3, not in isolation.
A notable finding: fine-tuned e5-large-v2 alone — with no reranker — outperformed pretrained e5-large-v2 in all configurations that included reranking. Fine-tuned e5-large-v2 reached NDCG@3 of 87.4% and Precision@3 of 92.2%, compared with 86.6% and 90.5% for the best pretrained-plus-reranker configuration. For enterprises with moderate compute constraints, this is a practical result: domain adaptation of a single retrieval model delivers better enterprise search quality than assembling a larger pretrained pipeline. Figure 6 presents the full results across all twelve experiment configurations.
Figure 5. Retrieval performance comparison — NDCG@3

Source: Infosys Topaz Fabric Studio
Figure 6. Evaluation results from the EnterpriseEM retrieval experiments
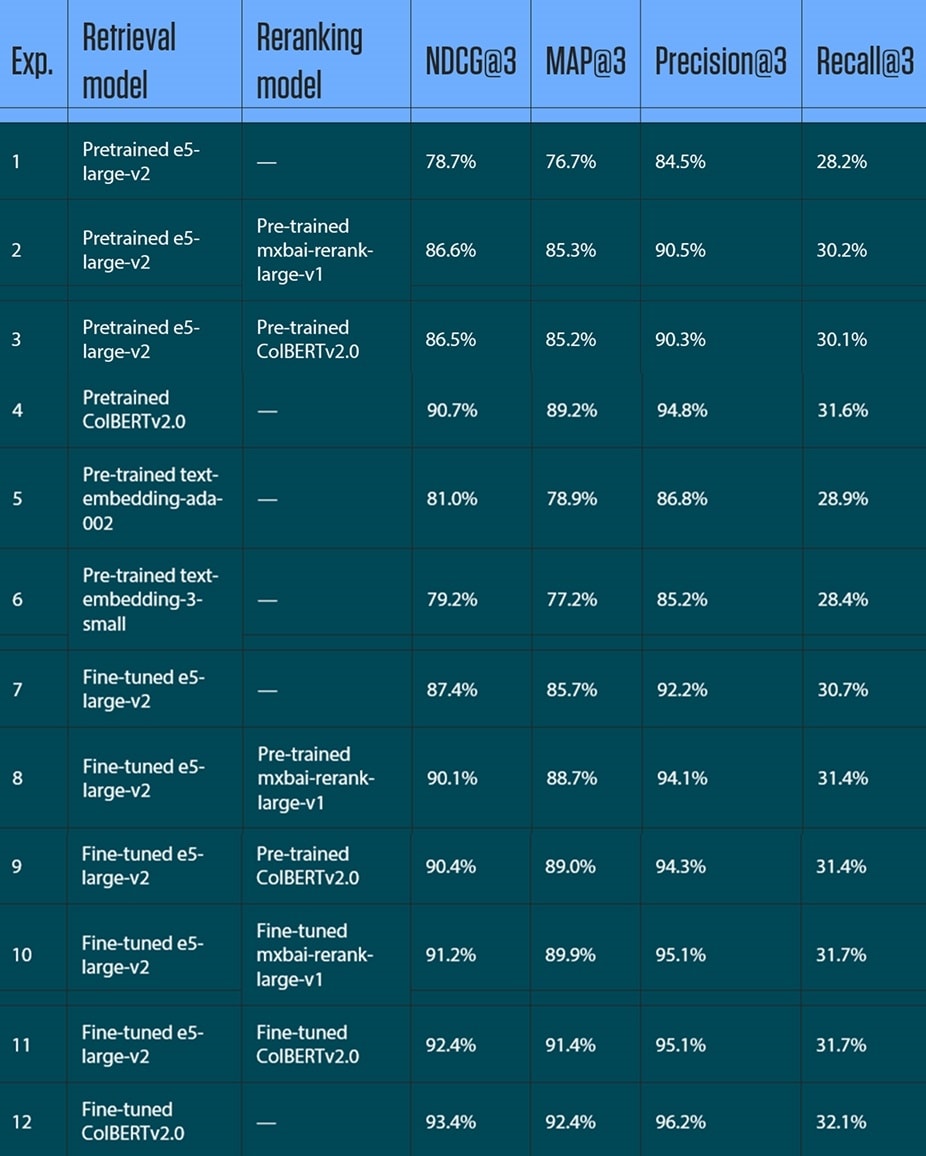
Note: Recall@3 reflects the fixed @3 retrieval window and should be read alongside Precision@3.
Source: Infosys Topaz Fabric Studio
The gains demonstrated by EnterpriseEM did not come from any single model choice. They came from the compound effect of careful data preparation, entity annotation, synthetic query generation, fine-tuning, and evaluation against actual user queries.
Enterprise AI pattern: Enterprise retrieval quality = Enterprise data + entity awareness + synthetic query generation + fine-tuning + real user evaluation
These findings reinforce a practical principle: A strong foundation model is important, but enterprise search performance ultimately improves when the model is adapted to the organization's data, terminology, and user behavior. Neither a better model nor better data alone explains the results — it is their combination that produces the improvement.
There is also an operational argument for a unified embedding approach. Maintaining separate embedding models for different internal search use cases adds hosting complexity and risks inconsistency across workflows. An enterprise-aligned embedding layer serves multiple search applications from a single well-maintained model, reducing operational overhead while improving consistency — a practical consideration for any team managing AI infrastructure at scale. Figure 7 contrasts conventional keyword-based search with the entity-aware, context-matched retrieval that enterprise alignment enables.
Figure 7. Conventional search vs. enterprise-aligned retrieval
Note: Enterprise-aligned retrieval focuses on understanding enterprise context rather than matching keywords alone.
Source: Infosys Topaz Fabric Studio
Several directions extend naturally from this work. More sophisticated semantic chunking strategies could better preserve meaning at document boundaries, particularly for long-form technical content where context frequently spans page breaks. Incorporating multimedia extraction — audio transcripts, video subtitles, image-embedded text — would expand coverage of enterprise knowledge that currently sits outside text-based pipelines. Applying the methodology to additional domains and organizations would test the generalizability of the enterprise adaptation approach beyond Infosys's specific terminology and content distribution. The broader direction is toward embedding systems maintained as living infrastructure: updated as enterprise language evolves, as new products are named, and as organizational priorities shift — rather than trained once and left static. That framing moves enterprise search from a one-time AI project toward a continuously improving knowledge system.
